
轻量级大语言模型MiniMind源码解读(十二):从白盒到黑盒,全面掌握大模型蒸馏技术
一、什么是知识蒸馏在传统监督学习中,模型学习的是ground-truth,而在知识蒸馏中,学生模型不仅学习ground-truth,还学习 教师模型的输出分布(soft targets),从而获得更丰富的上下文、模糊边界和类间关系信息。 最常见的方式,让学生学习教师的输出概率分布: $$\mathcal{L}_{\text{KD}} = T^2 \cdot \text{KL} \left( \text{softmax}\left(\frac{z_t}{T}\right) ,||, \text{softmax}\left(\frac{z_s}{T}\right) \right)$$ $z_t$: 教师模型 logits,$z_s$: 学生模型 logits $T$: 温度(temperature),用于平滑 logits 结合原始 Cross-Entropy loss: $$\mathcal{L}{\text{Total}} = \alpha \cdot \mathcal{L}{\text{CE}} + (1 - \alpha) \cdot...
轻量级大语言模型MiniMind源码解读(十一):LoRA-LLM轻量化微调的利器
一、LoRA的核心思想LoRA,全称 Low-Rank Adaptation of Large Language Models,是一种在 大模型中进行高效微调 的方法,目标是 只训练极少数参数 就能让模型适应新任务,避免重新训练整个大模型,从而可以在没有充足GPU显存的情况下快速在自己的数据集上对大模型做微调。 在Transformer、ViT、GPT等模型中,很多计算都包含线性层:$$y = W x$$ $$W \in \mathbb{R}^{d_{\text{out}} \times d_{\text{in}}}$$ LoRA 的做法是:不直接更新大模型参数W,而是在其旁边插入一个低秩矩阵BA,作为可训练的残差项:$$y = W x + BAx$$ 其中:$$ A \in \mathbb{R}^{r \times d_{\text{in}}} $$$$ B \in \mathbb{R}^{d_{\text{out}} \times r} $$$$ r \ll d_{\text{in}}, d_{\text{out}}...
轻量级大语言模型MiniMind源码解读(十):DPO-大模型对齐训练的新范式
DPO(Direct Preference Optimization) 是一种用于有监督指令微调后模型偏好对齐的训练方法,目标是让模型更倾向于输出人类偏好的回答(chosen),而不是次优回答(rejected)。 一、查看DPO训练数据集格式123456789import jsonpretrain_dataset_path=r'D:\MyFile\github\minimind-master\minimind_dataset\dpo.jsonl'with open(pretrain_dataset_path, 'r', encoding='utf-8') as f: for line_num, line in enumerate(f, 1): data = json.loads(line.strip()) break print(data.keys()) # dict_keys(['chosen',...
轻量级大语言模型MiniMind源码解读(九):指令微调详解-让大模型从“能说”变得“会听”
一、查看有监督微调数据集格式123456789import jsonpretrain_dataset_path=r'D:\MyFile\github\minimind-master\minimind_dataset\sft_mini_512.jsonl'with open(pretrain_dataset_path, 'r', encoding='utf-8') as f: for line_num, line in enumerate(f, 1): data = json.loads(line.strip()) break print(data.keys()) # dict_keys(['text'])print(data) 1234567891011{ 'conversations': [ { 'role':...
轻量级大语言模型MiniMind源码解读(八):LLM预训练-让大模型学会“说话”
当调用搭建好的MiniMindForCausalLM类实例化一个模型之后,模型的参数是随机的,这个阶段的模型没有任何语言能力,无法进行有意义的文本生成或理解。 预训练使用大规模的无监督语料对模型进行训练,使其具备“理解和生成自然语言”的基础能力,为后续的微调提供一个好的起点。 一、查看预训练数据集格式MiniMind预训练使用的数据集为pretrain_hq.jsonl,这是一个1.55GB的文件,里面包含了非常多条数据,这里查看其中的第一条数据作为示例: 123456789import jsonpretrain_dataset_path=r'D:\MyFile\github\minimind-master\minimind_dataset\pretrain_hq.jsonl'with open(pretrain_dataset_path, 'r', encoding='utf-8') as f: for line_num, line in enumerate(f, 1): data =...
从零开始实现YOLOv3
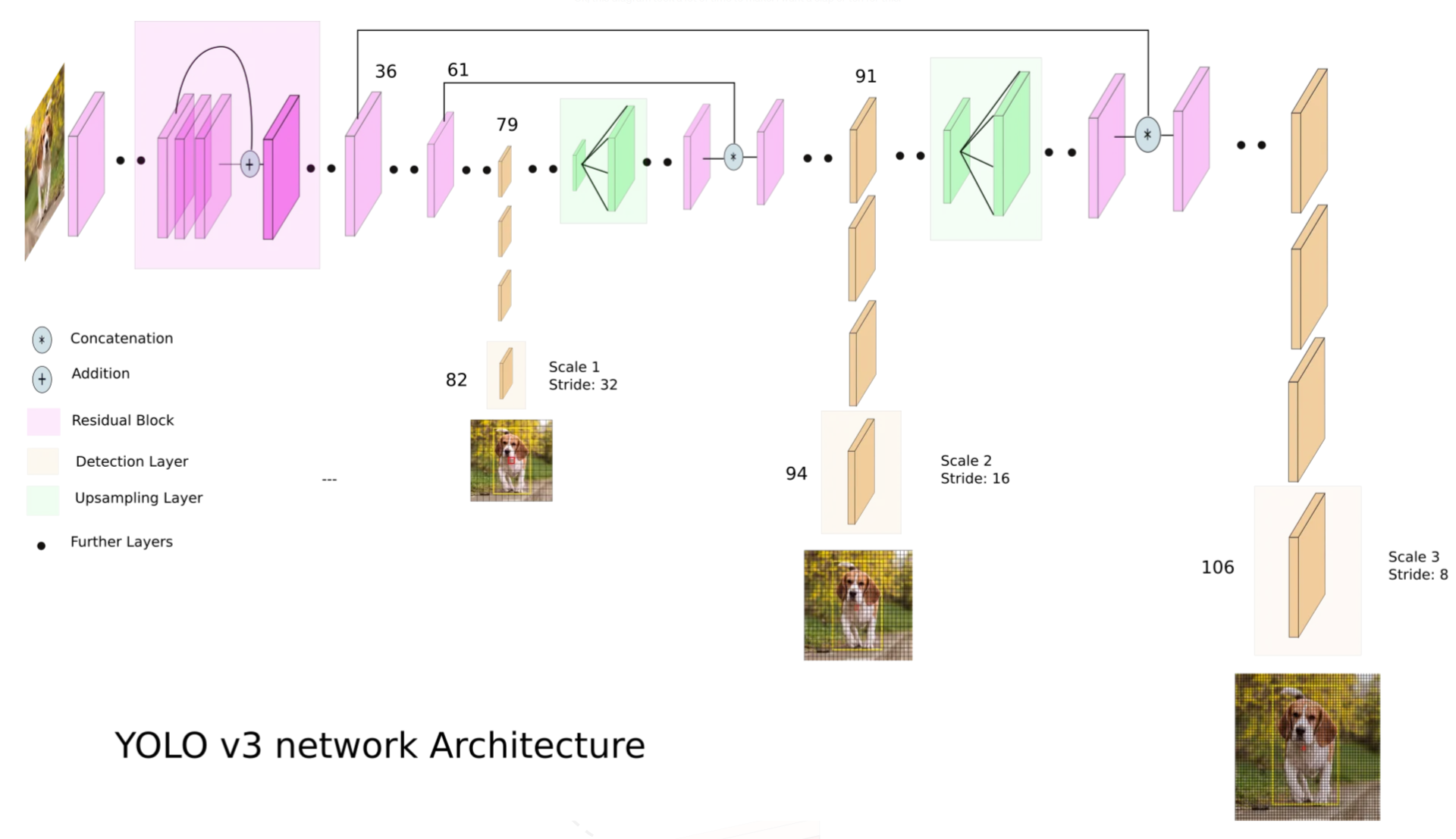
YOLOv1 vs YOLOv3 特性 YOLOv1 YOLOv3 基础网络 GoogLeNet(Inception v1) Darknet-53(基于ResNet) 多尺度预测 无(只将原图划分为7x7的网格) 支持多尺度预测(13x13, 26x26, 52x52,这些数字是不同特征图的尺寸) 锚框 无 使用锚框进行预测 损失函数 简单的均方误差MSE 改进的损失函数(MSE –> 交叉熵),增加了类别和置信度的加权 检测精度 较低,尤其对小物体检测较差 提高了精度,尤其对小物体检测能力增强。13 x 13 层负责检测大型物体,52 x 52 层检测较小的物体,26 x 26...
从零开始实现YOLOv1
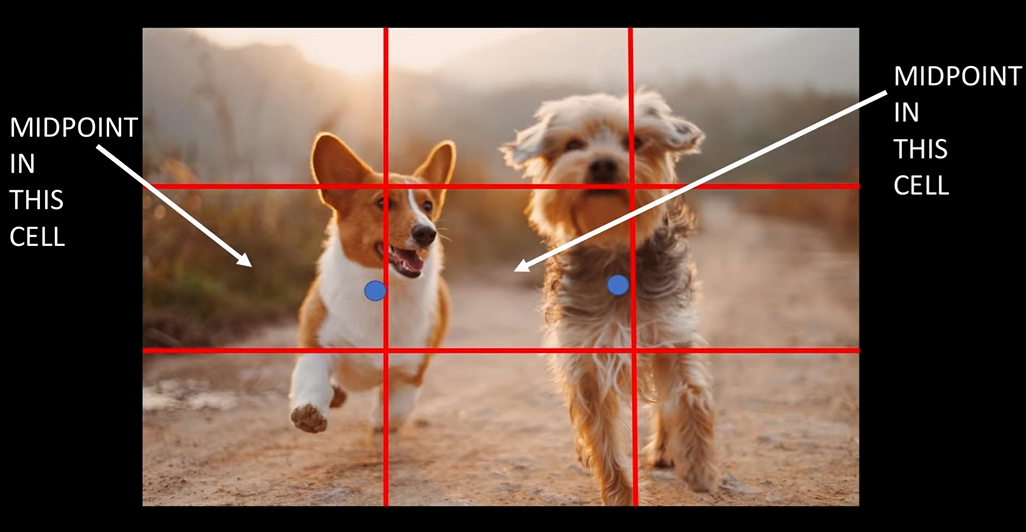
一、核心思想 YOLOv1 的核心思想是将目标检测问题视为一个回归问题,是一个直接从图像像素到边界框坐标及类别的映射。 输入图像通过一个单一的CNN进行处理,网络将图像划分为多个网格,每个网格负责检测图像中一个目标。 每个网格输出一个固定数量(B)的边界框和类别概率分布。 具体来说,Yolov1将一个448x448的原图片分割为7x7=49个网格(grid cell),每个grid cell预测: B(论文中B=2)个边界框(bbox)的坐标(x,y,w,h) B个bbox内各自是否包含目标的置信度confidence 1个类别概率分布C YOLOv1使用的训练集为pascal VOC2012,总共20个类别,因此每一个grid cell对应 (4+1)x2+20=30个预测参数。 二、标签格式标签分为预测标签prediction和真实标签target. target首先明确,每个物体都有一个中心点,如下图蓝色点所示。 每个gird cell都只负责预测某物体中心点落入该grid...

LLM指令微调:训练一个人工智能助手-大模型炼丹术(八)
在上一篇文章中,我们通过对预训练的 GPT-2 进行微调,得到了一个垃圾邮件分类器。事实上,这种方式是使用 GPT-2 的网络作为 backbone,在其输出后接一个分类头,来完成二分类任务。 在本文中,我们将介绍另一种微调方式:指令微调(Instruction Tuning)。 通过指令微调,我们可以打造一个对话机器人,就像你一直在使用的各种大语言模型应用那样 —— 它能够接收用户的自然语言指令,并输出相应的回复。 一、什么是指令微调?指令微调(Instruction Tuning) 是一种让预训练语言模型学会“听懂人话”的方法。它的核心思想是:通过监督微调(Supervised Fine-Tuning, SFT),让模型学习从「指令(Instruction)」到「输出(Response)」的映射。 这种方式与传统的分类、回归等任务不同,指令微调的数据格式通常是自然语言对话格式: 1234用户:请告诉我Python中如何定义一个函数?助手:你可以使用`def`关键词,例如:def my_function(): print("Hello...
LLM微调:训练一个垃圾邮件分类器-大模型炼丹术(七)
截止到现在,我们已经完成了LLM的整体架构搭建,是时候使用它来做一些下游的任务了。 我们所构建的LLM是GPT2,官方开源了它的预训练权重。如果只是使用GPT2实现文本续写等功能,可以直接加载预训练模型并进行推理。 然而,在实际的任务中,往往需要使用领域数据对LLM进行微调,以适配特定的下游任务,比如垃圾短信分类、对话生成、情感分析等。 本文使用一个垃圾邮件分类的任务,来说明如何基于预训练的GPT2在邮件数据集上进行微调,我们的目标是打造一个垃圾邮件分类器,输入一份邮件的内容,模型给出该邮件是否为垃圾邮件的分类结果。 一、准备垃圾邮件分类数据集在https://archive.ics.uci.edu/static/public/228/sms+spam+collection.zip下载垃圾邮件分类数据集,如下: 每一行是一个样本,其中第一列是label,空格后面的是label对应的邮件内容,label总共有两个值,表示这封邮件是否为垃圾邮件。 为乐便于后续数据预处理,将其读取为pandas的数据框格式: 12data_file_path =...
剖析LLM的解码策略-大模型炼丹术(六)
在使用训练好的LLM进行自回归预测下一个token时,我们会选择预测序列中最后一个token对应的预测tensor,作为解码操作的对象。 1234567# 获取模型的预测结果with torch.no_grad(): # 关闭梯度计算,加速推理 logits = model(idx_cond) # (batch, n_tokens, vocab_size)# 只关注最后一个时间步的预测结果# (batch, n_tokens, vocab_size) 变为 (batch, vocab_size)logit = logits[:, -1, :] 此时的logit就是用于解码的tensor,batch中的每一个都对应词汇表长度大小vocab_size的一个向量。 如何对该向量进行解码,得到要预测的下一个单词呢?本文介绍几种不同的解码策略。 一、贪心解码我们之前的解码策略是直接给logit应用softmax函数,然后使用argmax取概率值最大的数值对应的索引作为预测的下一个token ID,最后根据token...




