
异常处理_Python基础连载(十五)
开篇本期介绍Python的异常处理方法。 为什么需要做异常处理看下面的函数: 12def div(a,b): return a/b 这个函数用于求解两数相除的结果 我们可以调用它: 12345678#求解1/2>>> div(1,2)0.5#求解3/4>>> div(3,4)0.75 程序貌似没问题 但是我们知道,除数是不能为0的,现在来尝试让除数为0: 1234567>>> div(1,0)Traceback (most recent call last): File "<pyshell#2>", line 1, in <module> div(1,0) File "C:/Users/fanxi/Desktop/swe.py", line 2, in div return a/bZeroDivisionError: division by zero 毫无疑问,程序报错了! 报错信息也很明显:ZeroDivisionError:...

排序_不止于升降-Python基础连载(十四)
开篇本期将介绍排序方法,注意是方法而不是算法,因此更侧重方法的使用,而不对其内部细节的实现原理进行深究。 简单的列表(list)排序list自带有sort()方法可实现排序 默认是升序排列: 1234>>> lis=[1,3,2,5,4,8,6,9]>>> lis.sort()>>> lis[1, 2, 3, 4, 5, 6, 8, 9] 可通过传入reverse=True来实现降序: 1234>>> lis=[1,3,2,5,4,8,6,9]>>> lis.sort(reverse=True)>>> lis[9, 8, 6, 5, 4, 3, 2, 1] 你应该已经发现,上述的排序操作是直接在原列表中进行的。 除了上面的sort(),Python语言本身也有一种排序的函数,叫做sorted() 同样默认是升序排列: 1234>>> lis=[1,3,2,5,4,8,6,9]>>>...

Python将批量图片转pdf
最近在整理以前的书籍和资料,发现了一堆自己写的笔记: 摊开之后的画面是这样的: 丢了吧,太可惜,留着呢,又用不到,而且还占地方。思来想去,我决定将它们扫描做成电子档,永久储存在云端。 说干就干,先拿<操作系统笔记>开刀。我用手机摄像头充当扫描仪,开始了漫长的扫描,这真是个体力活。 许久,终于扫描完了,共134张图片。二话不说,在手机相册中选中扫描的图片,传送到手机wps,开始合成pdf… 然后就好了………………………………………………………吗? 事实是:wps最高只支持一次将50张图片合成pdf,而且还是在开会员的前提下才能操作。emm,...

kd树
...
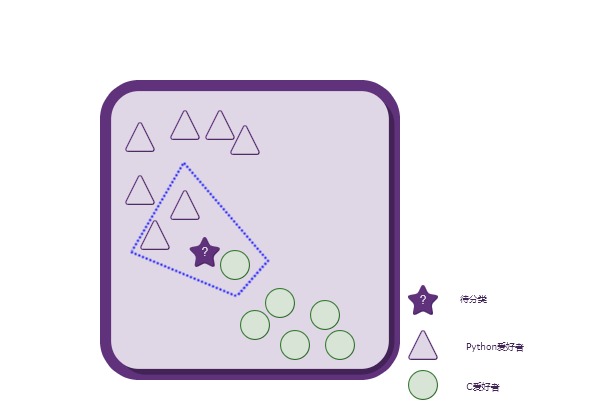
k-近邻算法
开篇k-近邻算法是比较简单的一种机器学习算法,其核心思想可以用一句话来概括:近朱者赤,近墨者黑。 在具体介绍该算法之前,先通过一个栗子对该算法做一个感性上的认识。 Python爱好者 or C爱好者 ? 上图中,每一个形状(三角形,圆形)都代表了一个人。总共有两种形状,说明这些人总共可以分为两类:Python爱好者、C爱好者。 三角形一共有7个,代表喜欢写Python的总共有7人; 圆形一共有6个,代表喜欢写C语言的总共有6人。 现在,突然来了一个不知道是喜欢写Python还是C语言(并且只可能属于其中之一)的人—–五角星,要求你来判定这个人所属的类别。 emm… 你可能会说,那看看图上距离这个人(五角星)最近的几个人所属类别就可以了啊!比如就看距离这个人最近的3个人:其中有两个人喜欢写Python,而只有一个人喜欢写C语言(如下图所示) 按照少数服从多数的原则,将这个新来的人(五角星)归类到三角形(Python爱好者)类别就搞定啦! ...


遗传算法的Python实现
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465import numpy as npimport matplotlib.pyplot as pltDNA_SIZE=10POP_SIZE=100CROSS_RATE=0.8MUTATION_RATE=0.003N_GENERATIONS=200X_BOUND=[0,5]#定义目标函数def F(x): return np.sin(10*x)*x+np.cos(2*x)*x#计算适应度,并使其大于0def get_fitness(pred): return pred+1e-3-np.min(pred)#将二进制串的DNA转为10进制数并限制范围在0到5之间def translateDNA(population): return...
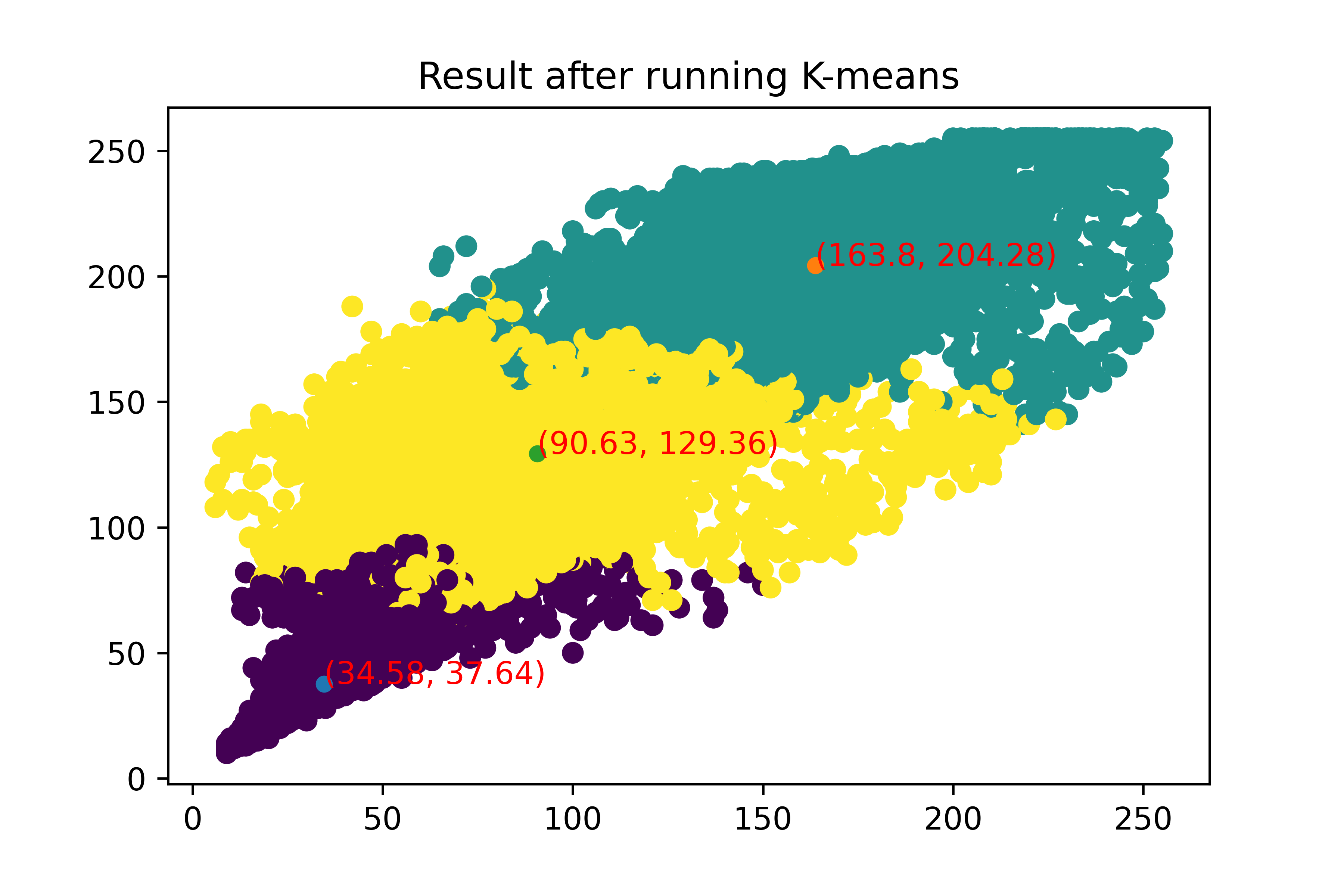
手写kmeans算法
开篇在本系列的前面几期中,我们介绍了包含决策树及其相关算法在内的一系列有监督学习算法。本期不妨换换口味,学习一种比较简单的无监督学习算法: k-means. k-means...

BrainF语言解释器的Python实现
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960def interp(code): data=[0 for _ in range(30000)] pc=0 ptr=0 st=[]#list模拟stack while(pc<len(code)): c=code[pc] print("正在处理字符'{}'".format(c)) if c=='<': ptr-=1 elif c=='>': ptr+=1 elif c=='+': data[ptr]+=1 ...

折腾Insightface-PyTorch的辛酸历程
2020年11月25号:配置环境(python3.5),运行prepare_data.py,成功提取训练集数据到imgs文件夹;但在提取测试集时报错,原因是python3.5及其之前的版本中的Path()都不继承自str类,于是手动给路径包裹了str(),成功提取除二进制格式保存的文件分别至单独的文件夹(blp后缀,不知道这是什么,先放着); 2020年11月26号:运行python train.py失败,从gihub issue了解到作者用了python3.6,于是重新配环境,试错,期间遇到了各种包装不上以及其他问题(发现作者还用了mxnet用于提取数据); 2020年11月27号:继续配环境,好像是配好了(python3.6),虽然还会报numpy的错误:ModuleNotFoundError: No module named 'numpy.core._multiarray_umath',但是并不影响模型的训练; 于是开始运行train.py,会报RuntimeError: cuda runtime error (2) : out of memory...




