一、稠密模型中的FFN 稠密模型(Dense Model)是指模型结构中所有的参数和计算路径在每次前向计算中都会被激活,与下一小节要介绍的稀疏模型MoE形成对比。
相比于原始Transformer中使用的FFN,这里的FFN引入了Gated结构,可以动态地控制信息流通(比如抑制/强调特定特征),增加了表达能力。目前很多SOTA模型(如 LLaMA、PaLM、GPT-NeoX、ChatGLM)都不再用原始 FFN,而是使用带门控机制(Gated)的前馈神经网络FFN。
这里对两者进行对比:
特性
标准 FFN
增强版 FFN(Gated)
激活函数
ReLU / GELU
GELU / SiLU / Swish 等
中间结构
单路计算
双路计算(乘积)
参数量
较少
多一个 Linear 层
非线性能力
一般
更强(引入乘法门控)
性能表现
基线
表现更好(SOTA 标配)
增强版FFN的代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 ACT2FN = { "relu" : F.relu, "gelu" : F.gelu, "silu" : F.silu } class FeedForward (nn.Module): def __init__ (self, config: dict ): super ().__init__() if config["intermediate_size" ] is None : intermediate_size = int (config["hidden_size" ] * 8 / 3 ) config["intermediate_size" ] = 64 * ((intermediate_size + 64 - 1 ) // 64 ) self .gate_proj = nn.Linear(config["hidden_size" ], config["intermediate_size" ], bias=False ) self .down_proj = nn.Linear(config["intermediate_size" ], config["hidden_size" ], bias=False ) self .up_proj = nn.Linear(config["hidden_size" ], config["intermediate_size" ], bias=False ) self .dropout = nn.Dropout(config["dropout" ]) self .act_fn = ACT2FN[config["hidden_act" ]] def forward (self, x ): return self .dropout( self .down_proj(self .act_fn(self .gate_proj(x)) * self .up_proj(x)) ) config = { "hidden_size" : 512 , "intermediate_size" : None , "dropout" : 0.1 , "hidden_act" : "silu" } ffn = FeedForward(config) x = torch.randn(2 , 16 , 512 ) out = ffn(x) print ("Output shape:" , out.shape)
这里的“门控机制”具体的逻辑是这样的:
首先,通过 gate = act_fn(gate_proj(x)) 得到门控信号(范围通常为[0, 1]或正数);
其次,通过 value = up_proj(x) 得到要被控制的信息通道;
接着,使用 gated = gate * value 应用门控,控制信息强度(本质上就是加权);
最后,使用output = down_proj(gated) 降维回去,门控完成。
二、稀疏模型MoE 2.1 MOE的工作原理 稠密模型适合中小规模模型结构,部署和训练更简单稳定,是大多数基础模型(如GPT、BERT、LLaMA)的核心形式。
但如果想让模型变得更大、更强,而又不想付出巨额推理开销,可以使用稀疏模型(比如MoE),这是一种更具扩展性的结构。其核心思想是:模型参数很多,但每次只激活其中一部分(部分专家),通过门控(Gating)机制选择专家进行预测、最后组合专家输出。
参考:
https://medium.com/@drahyhenc/mixture-of-experts%E5%AD%B8%E7%BF%92%E7%AD%86%E8%A8%98-80fae09a1b5e
在MiniMind中,MOE主要应用在Attention之后的FFN上。
原始的FFN使用的是我们上面定义的一个FeedForward类,而MOE的思想是将“原始FFN中只包含一个FeedForward”替换成“FFN中包含多个FeedForward”,其中每一个FeedForward都是一个专家,这乍看上去增加了很多参数,但是在实际的数据流动时,只会选择其中top-k个专家,也就是只会激活top-k个FeedForward,从而节省计算时间(但是还是需要将所有专家都加载到显存的,不省显存省时间,应对策略是把模型放在主内存里,需要的时候把相应的专家模型加载到显卡上进行推理)。
注意,在训练时,每一个专家都会被更新参数,训练完成后,“不同的专家擅长不同领域知识”这一目标就达成了,每个专家都得到了训练。在数据流向MOE时,会根据“学习到的经验”选择合适的专家进行处理。
现将MOE的执行流程总结为如下四步:
第一步、对每个 token,使用 MoEGate 打分,选择 top-k 个专家(例如 k=2)
第二步、只将 token 输入给这 k 个专家(repeat_interleave)
第三步、每个专家输出后加权求和(使用 gate 输出的 softmax 权重)
第四步、返回合并后的输出
相应的MOE主体实现代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 class MOEFeedForward (nn.Module): def __init__ (self, config ): super ().__init__() self .config = config self .experts = nn.ModuleList([ FeedForward(config) for _ in range (config.n_routed_experts) ]) self .gate = MoEGate(config) if config.n_shared_experts > 0 : self .shared_experts = nn.ModuleList([ FeedForward(config) for _ in range (config.n_shared_experts) ]) def forward (self, x ): """ x: [bsz, seq_len, hidden_size] """ identity = x orig_shape = x.shape bsz, seq_len, _ = x.shape topk_idx, topk_weight, aux_loss = self .gate(x) x = x.view(-1 , x.shape[-1 ]) flat_topk_idx = topk_idx.view(-1 ) if self .training: x = x.repeat_interleave(self .config.num_experts_per_tok, dim=0 ) y = torch.empty_like(x, dtype=torch.float16) for i, expert in enumerate (self .experts): mask = (flat_topk_idx == i) x_i = x[mask] if x_i.shape[0 ] > 0 : y[mask] = expert(x_i).to(y.dtype) y = y.view(*topk_weight.shape, -1 ) y = (y * topk_weight.unsqueeze(-1 )).sum (dim=1 ) y = y.view(*orig_shape) else : topk_weight = topk_weight.view(-1 , 1 ) y = self .moe_infer(x, flat_topk_idx, topk_weight) y = y.view(*orig_shape) if self .config.n_shared_experts > 0 : for expert in self .shared_experts: y = y + expert(identity) self .aux_loss = aux_loss return y @torch.no_grad() def moe_infer (self, x, flat_expert_indices, flat_expert_weights ): """ 推理阶段的 MoE 前向传播。按照专家编号将 token 分组,分别送入对应专家中计算后合并。 参数: - x: [bsz * seq_len, hidden_size] 所有 token 的表示(没有复制) - flat_expert_indices: [(bsz * seq_len) * top_k] 每个 token 被路由到的专家编号 - flat_expert_weights: [(bsz * seq_len) * top_k , 1] 每个专家对应的门控权重 """ expert_cache = torch.zeros_like(x) idxs = flat_expert_indices.argsort() tokens_per_expert = flat_expert_indices.bincount().cpu().numpy().cumsum(0 ) token_idxs = idxs // self .config.num_experts_per_tok for i, end_idx in enumerate (tokens_per_expert): start_idx = 0 if i == 0 else tokens_per_expert[i - 1 ] if start_idx == end_idx: continue expert = self .experts[i] exp_token_idx = token_idxs[start_idx:end_idx] expert_tokens = x[exp_token_idx] expert_out = expert(expert_tokens).to(expert_cache.dtype) expert_out.mul_(flat_expert_weights[idxs[start_idx:end_idx]]) expert_cache.scatter_add_( dim=0 , index=exp_token_idx.view(-1 , 1 ).repeat(1 , x.shape[-1 ]), src=expert_out ) return expert_cache
在上述代码中,MiniMind实现的MOE代码中还加入了共享的专家,这些专家都作用在原始输入上并加到输出上。
同时,针对推理场景,上述代码实现了高效地将 token 分派给不同专家并进行前向计算、加权输出、聚合结果等操作。其核心思想是:按照专家(0, 1, 2, …)对复制top_k倍的所有token索引进行分组排序。
为了便于理解推理过程,这里举一个具体的例子。
假设我们有以下配置:
假设有以下配置:
1 2 3 4 5 bsz = 2 seq_len = 2 hidden_size = 4 top_k = 2 num_experts = 3
也就是说:
总 token 数 = bsz * seq_len = 4
每个 token 分给 2 个专家,共 8 个分配记录
x.shape = [4, 4](4 个 token,每个是 4 维)
第一步、准备输入数据:
1 2 3 4 5 6 x = torch.tensor([ [0.1 , 0.2 , 0.3 , 0.4 ], [1.0 , 1.1 , 1.2 , 1.3 ], [2.0 , 2.1 , 2.2 , 2.3 ], [3.0 , 3.1 , 3.2 , 3.3 ], ])
第二步、top-k 专家分配(假设已经由 gate 模块得出):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 flat_expert_indices = torch.tensor([ 0 , 1 , 1 , 2 , 0 , 2 , 0 , 1 ]) flat_expert_weights = torch.tensor([ [0.9 ], [0.1 ], [0.3 ], [0.7 ], [0.4 ], [0.6 ], [0.5 ], [0.5 ], ])
第三步、推理阶段关键逻辑:
Step 1: idxs = flat_expert_indices.argsort()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 flat_expert_indices = [0 , 1 , 1 , 2 , 0 , 2 , 0 , 1 ] idxs = flat_expert_indices.argsort() idxs = [0 , 4 , 6 , 1 , 2 , 7 , 3 , 5 ]
Step 2: token_idxs = idxs // top_k1 2 3 4 5 6 7 8 idxs = [0 , 4 , 6 , 1 , 2 , 7 , 3 , 5 ] top_k = 2 token_idxs = = idxs // top_k = [0 , 2 , 3 , 0 , 1 , 3 , 1 , 2 ]
位置(flat_expert_indices的索引)
对应原始token
0, 1
token 0
2, 3
token 1
4, 5
token 2
6, 7
token 3
所以只要对 token index 整除 top_k 就能还原它是哪个 token。
Step 3: tokens_per_expert = flat_expert_indices.bincount().cpu().numpy().cumsum(0)1 2 3 4 flat_expert_indices = [0 , 1 , 1 , 2 , 0 , 2 , 0 , 1 ] tokens_per_expert = [3 , 6 , 8 ]
Expert 0:
1 2 3 4 5 分配到 idxs[0:3] = [0, 4, 6] 对应 token_idxs = [0, 2, 3] → 原始 token 的 index 从 x 取出 x[0], x[2], x[3] → 做前向 输出乘上 gate 权重 [0.9], [0.4], [0.5] 加到 expert_cache 的位置 0, 2, 3
Expert 1:
1 2 3 4 5 idxs[3:6] = [1, 2, 7] token_idxs = [0, 1, 2] 取出 x[0], x[1], x[2] 输出乘上 [0.1], [0.3], [0.5] 累加到 expert_cache 的位置 0, 1, 2
Expert 2:
1 2 3 4 5 idxs[6:8] = [3, 5] token_idxs = [1, 3] 取出 x[1], x[3] 输出乘上 [0.7], [0.6] 累加到 expert_cache 的位置 1, 3
expert_cache最终就是所有专家处理过的结果的加权累加和,每个token位置被多个专家处理,最后叠加权重输出。
最后,对训练和推理阶段的MOE执行过程做一个对比:
方面
训练阶段(Training)
推理阶段(Inference)
Token 是否复制
是,每个 token 被复制 top_k 次
否
处理顺序
每个 token 独立送入专家
将所有 token 按专家分组批量处理
加权方式
top_k 输出加权平均用 scatter_add_() 加权累加
效率
低(但梯度计算方便)
高(节省内存,计算高效)
适用场景
训练
推理(部署)
多专家叠加
加权平均
加权叠加
2.2 MOE的负载均衡 https://ai.gopubby.com/deepseek-v3-explained-3-auxiliary-loss-free-load-balancing-4beeb734ab1f
https://www.linkedin.com/pulse/what-main-benefit-mixture-experts-moe-models-qi-he-nkgbe?utm_source=rss&utm_campaign=articles_sitemaps&utm_medium=google_news
在MOE_Gate打分的时候,可能偏向于给某几个专家打高分,导致token总是交给这几个专家处理,其余的专家总是处于空闲状态,这就是负载的不均衡,也称之为路由坍塌(Route collapse)。
路由坍塌的存在,会影响最终的模型效果。具体来说,由于过载的专家接收更多的输入token,它们也会积累更大的梯度,并且比负载较轻的专家学习得更快。结果,过载的专家和负载较轻的专家的梯度在幅度和方向上可能会发散,使得训练过程更难收敛。
为了实现专家的负载均衡,有许多不同的技术被提出来以处理这个问题。
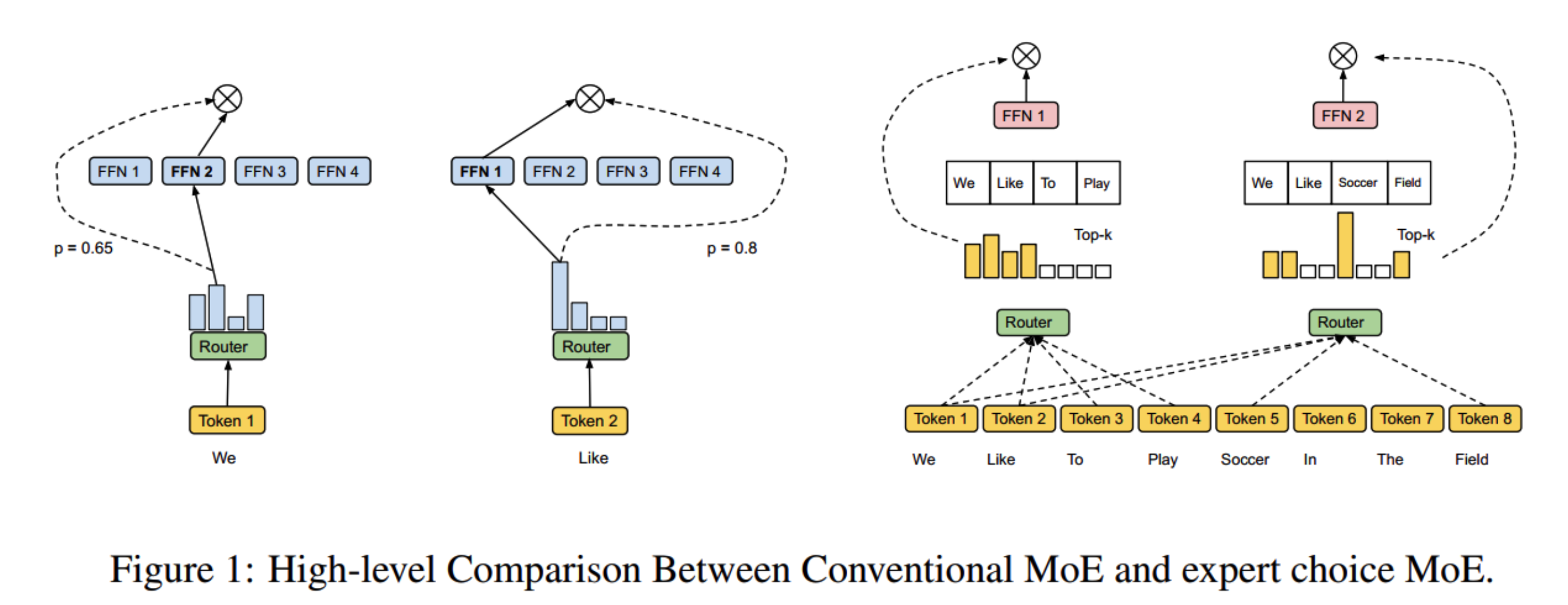
2.2.1 专家选择(Expert Choice) 在原始的MOE中,是每个token给出对于所有专家的打分,然后每个token各自选出得分top_k大的top_k个专家,这是一个token选择专家的过程。负载不均衡指的就是某些专家一直没有被token选择。
Expert Choice将原先的“token选择专家”改成“专家选择要处理的token”:
每个专家都预先设置一个专家容量k,因此不会出现某些专家一直没有token可处理的情况。
然而,这种方法也有可能出现某些token使用了多个专家,而有些token只使用了很少甚至0个专家的情况。
2.2.2 辅助损失 在MiniMind源码中使用的是辅助损失的方式来应对路由坍塌问题。
在计算出每个token对于所有专家的打分后,每个token会选择top_k个得分高的专家进行后续处理。我们可以根据这里每个专家的得分(平均打分),以及每个专家实际被选中使用的频率(实际负载),来定义损失函数。具体来说,如果每个专家频繁被选中,并且每个专家的得分总是高于其它专家,那么就会惩罚这个专家。由于此时该专家对应的“平均打分 x 实际负载”比较高,将这个乘积作为一项loss进行惩罚。
基于这种思想,MiniMind分别从序列维度和整个batch维度进行了上述辅助损失函数的实现,相应的解释已经写在代码注释中,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 class MoEGate (nn.Module): def __init__ (self, config ): super ().__init__() self .config = config self .top_k = config.num_experts_per_tok self .n_routed_experts = config.n_routed_experts self .scoring_func = config.scoring_func self .alpha = config.aux_loss_alpha self .seq_aux = config.seq_aux self .norm_topk_prob = config.norm_topk_prob self .gating_dim = config.hidden_size self .weight = nn.Parameter(torch.empty((self .n_routed_experts, self .gating_dim))) self .reset_parameters() def reset_parameters (self ) -> None : import torch.nn.init as init init.kaiming_uniform_(self .weight, a=math.sqrt(5 )) def forward (self, hidden_states ): """ Args: hidden_states: [bsz, seq_len, hidden_dim] Returns: topk_idx: [bsz * seq_len, top_k] - top-k 专家索引 topk_weight: [bsz * seq_len, top_k] - top-k 专家对应的权重 aux_loss: scalar - 辅助损失,用于平衡专家负载 """ bsz, seq_len, h = hidden_states.shape hidden_states = hidden_states.view(-1 , h) logits = F.linear(hidden_states, self .weight, None ) if self .scoring_func == 'softmax' : scores = logits.softmax(dim=-1 ) else : raise NotImplementedError(f'insupportable scoring function for MoE gating: {self.scoring_func} ' ) topk_weight, topk_idx = torch.topk(scores, k=self .top_k, dim=-1 , sorted =False ) if self .top_k > 1 and self .norm_topk_prob: denominator = topk_weight.sum (dim=-1 , keepdim=True ) + 1e-20 topk_weight = topk_weight / denominator if self .training and self .alpha > 0.0 : scores_for_aux = scores aux_topk = self .top_k topk_idx_for_aux_loss = topk_idx.view(bsz, -1 ) if self .seq_aux: scores_for_seq_aux = scores_for_aux.view(bsz, seq_len, -1 ) ce = torch.zeros(bsz, self .n_routed_experts, device=hidden_states.device) ce.scatter_add_( dim = 1 , index = topk_idx_for_aux_loss, src = torch.ones(bsz, seq_len * aux_topk, device=hidden_states.device) ).div_(seq_len * aux_topk / self .n_routed_experts) aux_loss = (ce * scores_for_seq_aux.mean(dim=1 )).sum (dim=1 ).mean() * self .alpha else : mask_ce = F.one_hot( topk_idx_for_aux_loss.view(-1 ), num_classes=self .n_routed_experts ) ce = mask_ce.float ().mean(0 ) Pi = scores_for_aux.mean(0 ) fi = ce * self .n_routed_experts aux_loss = (Pi * fi).sum () * self .alpha else : aux_loss = 0 return topk_idx, topk_weight, aux_loss
至此,MiniMind所涉及的组件就已经全部搭建完成了,在下一篇文章中,我们将这些组件组合起来,构建MiniMind网络,欢迎持续关注~