轻量级大语言模型MiniMind源码解读(五):魔改的注意力机制,细数当代LLM的效率优化手段
MiniMind中的注意力机制包含了KV cache,GQA,Flash Attention等技术。
一、KV Cache
KV Cache(Key-Value Cache)是在Transformer自回归模型(如GPT)推理阶段中,为了加速推理、减少重复计算而引入的缓存机制。
具体来说,在推理时,为每个生成的token计算K和V矩阵,KV Cache将这些矩阵存储在内存中,以便在生成后续token时,我们只需为新的token计算K和V,而不是重新计算所有当前已生成token的K和V。
解码器以自回归的方式工作,如下面的GPT-2文本生成示例所示:

在解码器的自回归生成中,给定一个输入,模型预测下一个token,然后在下一步将组合输入进行下一次预测。
这种自回归行为重复了一些操作,可以通过放大解码器中计算的掩码缩放点积注意力计算来更好地理解这一点:

这里对是否使用KV Cache的QK计算过程进行对比:
上图中,紫色是从缓存中获取的,绿色是计算得到的,灰色是根据causal机制(当前token只能看到自己以及之前的信息)被mask掉的(因此无需计算)。通过这些动图,可以很清晰的观察到使用KV Cache可以减少许多token的K和V向量的重复计算。
举个例子,假设在执行推理时,batch_size=1, 当前已经累计生成的toke数量为seq_len=511,hidden_size=512,num_query_heads = 8,num_key_value_heads = 2,
则head_dim = hidden_size / num_query_heads = 64,已经缓存的KV的shape均为[batch_size, seq_len,num_key_value_heads,head_dim] = [1,511,2,64],并且将刚预测的新的token与已经预测的511个拼接在一起,总共512个,根据KV Cache的原理,在预测下一个token时,只需要计算新加入的第512个token(记作x)与所有512个token之间的注意力。
x 经过embedding层得到的shape为 [batch_size,seq_len,hidden_size]=[1,1,512],然后通过线性层投影出xk和xv,shape都是 [batch_size,seq_len,num_key_value_headshead_dim]=[1,1,264],然后reshape成[batch_size,seq_len,num_key_value_heads,head_dim]=[1,1,2,64],这就是最新生成的token的q和v,将其与缓存的前面512个token的q和v进行拼接,就得到了本次预测需要的KV矩阵,shape为concat([1,511,2,64],[1,1,2,64]) –> [1,512,2,64].
另外,这里快速介绍一下Transformer中的qkv,以加深理解:
在Transformer的翻译任务中,encoder接收[bsz,src_seq_len,hidden_size]的token embedding,经过attention等层输出[bsz,src_seq_len,hidden_size]作为kv(只生成一次),供q多轮查询,q来自decoder,shape为[bsz,total_seq_len,hidden_size],total_seq_len是decoder当前处理(已经生成)的序列长度。
二、MHA,MQA和GQA
在Transformer中,每一层的注意力通常是基于多头注意力(Multi-Head Attention, MHA)实现的。这个模块的核心操作是将模型的总隐藏维度$d_{model}$(MiniMind中也称之为hidden_dim)
拆分为多个“头”(heads),每个头独立地进行注意力计算,然后再将它们的结果拼接起来,投影回原始空间。
通过”多头”操作,每个头(head)可以专注不同的子空间,模型可以更好的捕捉多种不同的语义/结构关系。多个头并行,相当于多个子空间并行抽取特征,最后拼接后再映射,增强了模型的非线性表达能力。
既然”多头”操作有这些优势,那为什么还会出现GQA、MQA这种注意力机制呢?
实际上,MHA的并行多头机制虽然表达能力强,但它存在计算和内存上的开销问题。具体表现为:
- 在标准MHA中,每个头都需要独立的Q、K、V,共3个线性层,存储开销是成倍的。
- 在推理时,尤其是大模型部署中,每个token都要执行所有头的K/V计算并缓存,非常耗显存。
为了减少存储占用,出现了MQA,其核心思想是:每个注意力头依然保留独立的Query(Q)向量,但所有注意力头共享一组Key(K)和Value(V)向量。这样大大减少了计算和缓存中K/V的冗余部分。尤其在解码器结构中(如 GPT 系列),推理阶段需要缓存每个token的key/value,如果每个头都独立缓存,会造成巨大的显存压力,MQA 可以显著降低这种开销。
然而,由于K和V只有1个头,所有头的Q都共享这1个K和V,导致每个Query头无法获取独立的上下文信息,只能从同一组Key/Value中抽取信息。这在一定程度上限制了模型捕捉多样化注意力模式的能力,尤其是在建模复杂依赖关系或多语义对齐时可能效果不如标准MHA。
因此,虽然MQA在计算和显存占用方面具有显著优势,但也带来了表达能力的折损。这正是GQA出现的原因:通过让多个Q头共享部分(而不是全部)K/V子空间,GQA在保持效率的同时,部分恢复了MHA的灵活性和多样性,是一种性能与效率的折中设计。
这张图清晰的展示了MHA,MQA和GQA的区别:
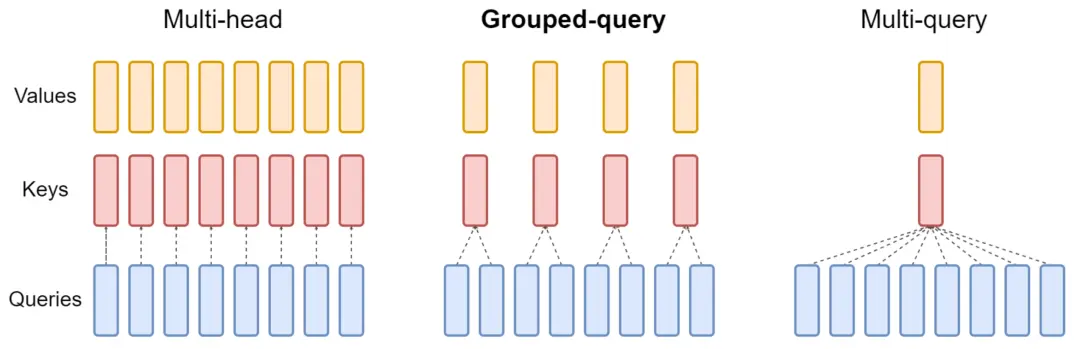
注意,在计算注意力时,虽然MQA/GQA头数少,但通常会通过repeat/broadcast扩展回与Q相同的头数来做注意力计算,因此:从注意力矩阵计算(即 Q @ K^T 和 attention @ V)的FLOPs来上看,三者几乎是一样的。
但计算量不等于性能损耗,区别主要在:
- KV的投影次数(线性层)少了:MHA每头独立,KV线性投影各做num_heads次,MQA只做一次,GQA做M次(M是一个大于1 & 小于num_heads,且能够被num_heads整除的数)。这样一来, KV cache大幅减少,因为缓存的head 数是1或M,不是num_heads。
- KV的repeat操作可以高效实现:比如FlashAttention可以使用broadcast或index select避免真的物理复制(repeat)。
现在来举个例子,对比三者的存储开销,这里我们只比较注意力中K/V缓存的显存占用(推理时需保留),忽略 Q。
假设总隐藏维度$d_{model}$=4096,num_heads=32,seq_len=1024,batch_size=1,有head_dim=$d_{model}$//num_heads=4096//32=128,在GQA中将总共num_heads=32个Q向量分成8组。
每个float32占用4字节,每种方法的总存储占用(Byte)= batch_size × num_kv_heads × seq_len × head_dim × float_size
| 类型 | num_kv_heads | 计算公式 | 显存占用(Byte) | 显存占用(MB) |
|---|---|---|---|---|
| MHA | 32 | 1×32×1024×128×4 = 16,777,216 | 16,777,216 | 16 MB |
| GQA (8组) | 8 | 1×8×1024×128×4 = 4,194,304 | 4,194,304 | 4 MB |
| MQA | 1 | 1×1×1024×128×4 = 524,288 | 524,288 | 0.5 MB |
实际部署中,节省的是decoder每个token的KV缓存量,对于长序列推理影响显著。
如果真的希望减少计算量(而不仅仅是缓存量),就不能repeat kv,而是要修改attention的实现方式,让多个Q共享一个K/V。
三、Flash Attention
Flash Attention是一种显存优化 + 更快计算的注意力实现,数学本质不变,只是在实现细节上做了大量工程优化,尤其适用于长序列Transformer模型(如LLM)。
它通过采用流式分块计算,在softmax前后都不存中间结果,避免显存瓶颈。提供更高吞吐、更长上下文能力而不会爆显存。
在PyTorch中,可以简单的通过torch.nn.functional.scaled_dot_product_attention直接使用Flash Attention。
以上介绍的KV cache,GQA,Flash Attention均已在MiniMind的Attention模块进行了实现,如下:
1 | from typing import Optional, Tuple, List, Union |
这里涉及到3个mask,其作用分别为:
- 屏蔽未来信息:torch.triu(torch.full((seq_len, seq_len), float(“-inf”), device=scores.device),diagonal=1).unsqueeze(0).unsqueeze(0)
- padding的token不参与注意力计算:attention_mask,shape是[batch_size,seq_len]。在MiniMind训练时,默认是None,可根据实际情况进行调整。
- 训练时,padding的token不参与loss计算:loss = (loss * loss_mask).sum() / loss_mask.sum() [这个来自训练代码]
参考:





