一、从DINO到DINOv2
DINO发布后,iBOT在DINO的基础上进行了扩展,引入了Patch-level蒸馏等新特性。随后,DINOv2又在iBOT的思想基础上进行了进一步改进,提升了训练稳定性和特征表达能力。
可以说:
1
2
3
4
| DINO → iBOT → DINOv2
iBOT = DINO + Patch-level 蒸馏等改进
DINOv2 = iBOT + 训练稳定性 & 特征表达能力提升等技巧
|
关于DINO的内容在上一篇文章中已有介绍,因此本文首先介绍iBOT,再讲DINOv2的独特trick。
二、iBOT
iBOT延续了DINO的全部思想,包括教师网络EMA更新参数,[CLS] token 蒸馏对齐等。如果你去查看官方github代码,会发现iBOT的代码就是基于DINO的代码框架进行二次修改的。此外,iBOT还引入了类BERT的MLM训练思路,接下来对这些方法进行逐一讲解。
2.1 和DINO一致的多视角增强策略
iBOT的数据增强逻辑和DINO是一致的,直接上代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
| class DataAugmentationiBOT(object):
def __init__(self, global_crops_scale, local_crops_scale, global_crops_number, local_crops_number):
flip_and_color_jitter = transforms.Compose([
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomApply(
[transforms.ColorJitter(
brightness=0.4, contrast=0.4, saturation=0.2, hue=0.1)],
p=0.8
),
transforms.RandomGrayscale(p=0.2),
])
normalize = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406),
(0.229, 0.224, 0.225)),
])
self.global_crops_number = global_crops_number
self.global_transfo1 = transforms.Compose([
transforms.RandomResizedCrop(224, scale=global_crops_scale, interpolation=Image.BICUBIC),
flip_and_color_jitter,
utils.GaussianBlur(1.0),
normalize,
])
self.global_transfo2 = transforms.Compose([
transforms.RandomResizedCrop(224, scale=global_crops_scale, interpolation=Image.BICUBIC),
flip_and_color_jitter,
utils.GaussianBlur(0.1),
utils.Solarization(0.2),
normalize,
])
self.local_crops_number = local_crops_number
self.local_transfo = transforms.Compose([
transforms.RandomResizedCrop(96, scale=local_crops_scale, interpolation=Image.BICUBIC),
flip_and_color_jitter,
utils.GaussianBlur(p=0.5),
normalize,
])
def __call__(self, image):
"""
输入:
image: 原始 PIL Image (H, W, 3)
输出:
crops: 一个 list,包含 global_crops_number + local_crops_number 张增强后的图像
- 前 global_crops_number 张:224x224 全局视图
- 后 local_crops_number 张:96x96 局部视图
每张图 shape = [3, H, W] (Tensor)
"""
crops = []
crops.append(self.global_transfo1(image))
for _ in range(self.global_crops_number - 1):
crops.append(self.global_transfo2(image))
for _ in range(self.local_crops_number):
crops.append(self.local_transfo(image))
return crops
|
2.2 在DINO的CLS token 蒸馏基础上,新增类BERT的patch token蒸馏
DINO里,蒸馏的对象是[CLS] token,也就是整张图的全局表征,目标是让学生网络的全局特征去拟合教师网络的全局特征。
而iBOT在此基础上,更进一步,不仅蒸馏[CLS] token,还蒸馏patch token(局部表征)。
具体做法和BERT的Masked Language Modeling(MLM)类似,即:
在学生网络的输入图像中,随机选择一部分patch进行mask,而教师网络则看到完整图像。学生网络需要预测被mask掉的patch的embedding,目标是尽可能接近教师网络在这些位置上的patch embedding。
这是一种高级语义向量的预测,而不像MAE那样直接预测具体的像素值。
因此iBOT的总损失由两部分组成:
- CLS-level Loss(和DINO一致,跨视图蒸馏全局语义)
- Patch-level Loss(类似BERT,预测缺失局部patch表征)
总的loss为两者的加权和,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
| class IBOTLoss(nn.Module):
def __init__(self, out_dim, patch_out_dim, lambda_patch=1.0, student_temp=0.1, teacher_temp=0.04, center_momentum=0.9):
super().__init__()
self.out_dim = out_dim
self.patch_out_dim = patch_out_dim
self.lambda_patch = lambda_patch
self.student_temp = student_temp
self.teacher_temp = teacher_temp
self.center_momentum = center_momentum
self.register_buffer("center_cls", torch.zeros(1, out_dim))
self.register_buffer("center_patch", torch.zeros(1, patch_out_dim))
def forward(self, student_cls, teacher_cls, student_patch, teacher_patch, epoch):
"""
student_cls: [ (2+N)*B , out_dim ] # 学生 CLS 输出
teacher_cls: [ 2*B , out_dim ] # 教师 CLS 输出
student_patch: [ (2+N)*B , P , patch_out_dim ] # 学生 patch token 输出
teacher_patch: [ 2*B , P , patch_out_dim ] # 教师 patch token 输出
out_dim 是image-->backbone-->fc head的维度
patch_out_dim 是image-->backbone的维度
"""
teacher_cls_centered = (teacher_cls - self.center_cls) / self.teacher_temp
teacher_cls_soft = torch.softmax(teacher_cls_centered, dim=-1)
student_cls_scaled = student_cls / self.student_temp
cls_loss = -(teacher_cls_soft.detach() * F.log_softmax(student_cls_scaled, dim=-1)).sum(dim=-1).mean()
mask = (torch.rand(student_patch.shape[0], student_patch.shape[1], device=student_patch.device) > 0.15)
teacher_patch_centered = (teacher_patch - self.center_patch) / self.teacher_temp
teacher_patch_soft = torch.softmax(teacher_patch_centered, dim=-1)
student_patch_scaled = student_patch / self.student_temp
patch_loss = -(teacher_patch_soft.detach() * F.log_softmax(student_patch_scaled, dim=-1))
patch_loss = (patch_loss.sum(dim=-1) * mask).sum() / mask.sum()
loss = cls_loss + self.lambda_patch * patch_loss
return loss
@torch.no_grad()
def update_center(self, teacher_cls, teacher_patch):
"""
更新教师中心向量 (EMA)
teacher_cls: [2*B, out_dim]
teacher_patch: [2*B, P, patch_out_dim]
"""
batch_center_cls = teacher_cls.mean(dim=0, keepdim=True)
batch_center_patch = teacher_patch.mean(dim=(0,1), keepdim=True)
self.center_cls = self.center_cls * self.center_momentum + batch_center_cls * (1 - self.center_momentum)
self.center_patch = self.center_patch * self.center_momentum + batch_center_patch * (1 - self.center_momentum)
|
注意,由于iBOT多了一个patch token的预测,因此不仅需要维护教师网络的cls token center,还要额外维护一个patch token center。
上述是一个简化版本的代码,便于理解,完整的iBOTLoss代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
| class iBOTLoss(nn.Module):
def __init__(self, out_dim, patch_out_dim, ngcrops, nlcrops,
warmup_teacher_temp, teacher_temp,
warmup_teacher_temp2, teacher_temp2,
warmup_teacher_temp_epochs, nepochs,
student_temp=0.1, center_momentum=0.9, center_momentum2=0.9,
lambda1=1.0, lambda2=1.0, mim_start_epoch=0):
super().__init__()
self.student_temp = student_temp
self.center_momentum = center_momentum
self.center_momentum2 = center_momentum2
self.ngcrops = ngcrops
self.nlcrops = nlcrops
self.ncrops = ngcrops + nlcrops
self.lambda1 = lambda1
self.lambda2 = lambda2
self.register_buffer("center", torch.zeros(1, out_dim))
self.register_buffer("center2", torch.zeros(1, 1, patch_out_dim))
self.teacher_temp_schedule = np.concatenate((
np.linspace(warmup_teacher_temp, teacher_temp, warmup_teacher_temp_epochs),
np.ones(nepochs - warmup_teacher_temp_epochs) * teacher_temp
))
self.teacher_temp2_schedule = (
np.concatenate((
np.linspace(warmup_teacher_temp2, teacher_temp2, warmup_teacher_temp_epochs),
np.ones(nepochs - warmup_teacher_temp_epochs) * teacher_temp2
)) if mim_start_epoch == 0 else np.concatenate((
np.ones(mim_start_epoch) * warmup_teacher_temp2,
np.linspace(warmup_teacher_temp2, teacher_temp2, warmup_teacher_temp_epochs),
np.ones(nepochs - warmup_teacher_temp_epochs - mim_start_epoch) * teacher_temp2
))
)
def forward(self, student_output, teacher_output, student_local_cls, student_mask, epoch):
"""
计算 student 与 teacher 的蒸馏 loss
"""
student_cls, student_patch = student_output
teacher_cls, teacher_patch = teacher_output
if student_local_cls is not None:
student_cls = torch.cat([student_cls, student_local_cls])
student_cls = student_cls / self.student_temp
student_cls_c = student_cls.chunk(self.ncrops)
student_patch = student_patch / self.student_temp
student_patch_c = student_patch.chunk(self.ngcrops)
temp = self.teacher_temp_schedule[epoch]
temp2 = self.teacher_temp2_schedule[epoch]
teacher_cls_c = F.softmax((teacher_cls - self.center) / temp, dim=-1)
teacher_cls_c = teacher_cls_c.detach().chunk(self.ngcrops)
teacher_patch_c = F.softmax((teacher_patch - self.center2) / temp2, dim=-1)
teacher_patch_c = teacher_patch_c.detach().chunk(self.ngcrops)
total_loss1, n_loss_terms1 = 0, 0
total_loss2, n_loss_terms2 = 0, 0
for q in range(len(teacher_cls_c)):
for v in range(len(student_cls_c)):
if v == q:
loss2 = torch.sum(
-teacher_patch_c[q] * F.log_softmax(student_patch_c[v], dim=-1),
dim=-1
)
mask = student_mask[v].flatten(-2, -1)
loss2 = torch.sum(loss2 * mask.float(), dim=-1) / mask.sum(dim=-1).clamp(min=1.0)
total_loss2 += loss2.mean()
n_loss_terms2 += 1
else:
loss1 = torch.sum(
-teacher_cls_c[q] * F.log_softmax(student_cls_c[v], dim=-1),
dim=-1
)
total_loss1 += loss1.mean()
n_loss_terms1 += 1
total_loss1 = total_loss1 / n_loss_terms1 * self.lambda1
total_loss2 = total_loss2 / n_loss_terms2 * self.lambda2
total_loss = dict(
cls=total_loss1, patch=total_loss2, loss=total_loss1 + total_loss2
)
self.update_center(teacher_cls, teacher_patch)
return total_loss
@torch.no_grad()
def update_center(self, teacher_cls, teacher_patch):
"""
更新 teacher 的中心
"""
cls_center = torch.sum(teacher_cls, dim=0, keepdim=True)
dist.all_reduce(cls_center)
cls_center = cls_center / (len(teacher_cls) * dist.get_world_size())
self.center = self.center * self.center_momentum + cls_center * (1 - self.center_momentum)
patch_center = torch.sum(teacher_patch.mean(1), dim=0, keepdim=True)
dist.all_reduce(patch_center)
patch_center = patch_center / (len(teacher_patch) * dist.get_world_size())
self.center2 = self.center2 * self.center_momentum2 + patch_center * (1 - self.center_momentum2)
|
举个例子,假设batch_size=64,局部crop数量N=8,前向传播过程如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
student_output, student_output_tokens = student(images)
teacher_output, teacher_output_tokens = teacher(images[:2])
loss = ibot_loss(
student_output,
teacher_output,
student_output_tokens,
teacher_output_tokens,
epoch
)
with torch.no_grad():
m = momentum_schedule[step]
for param_q, param_k in zip(student.parameters(), teacher.parameters()):
param_k.data.mul_(m).add_(param_q.data * (1. - m))
ibot_loss.update_center(teacher_output, teacher_output_tokens)
|
三、DINOv2的模型优化trick
3.1 更强大的数据处理管道
论文构建了LVD-142M数据集,整个流程仅依赖图像,不需要文本或元数据,主要包括数据来源、去重和自监督检索三个步骤。
3.1.1. 数据来源
- 精选数据(Curated):ImageNet-22k、ImageNet-1k训练集、Google Landmarks等。
- 非精选数据(Uncurated):从公开网络爬取的原始图像,经过URL筛选、去重、NSFW过滤和模糊面部处理,得到约12亿张图像。
3.1.2. 去重
- 对非精选数据去除近似重复,增加多样性。
- 移除测试/验证集中的重复图像,避免数据泄漏。
3.1.3 自监督图像检索
- 使用自监督ViT-H/16网络计算图像嵌入。
- 对非精选数据做k-means聚类。
- 检索策略:
- 大查询集:每张图检索4个最近邻。
- 小查询集:从对应簇中采样图像。
3.1.4 实现细节
- 去重与检索依赖Faiss GPU 加速索引。
- 使用20节点×8GPU集群,全流程耗时<2天。
3.2 更强大的训练trick
3.2.1 头权重解耦(Untying head weights)
在早期工作的消融实验中,共享投影头(DINO与iBOT共用一个MLP)在小规模数据或低分辨率训练时可以带来更稳定的训练和略微的性能提升。
但是在大规模训练和高分辨率图像下,共享头容易导致冲突:
- DINO的图像级损失关注全局特征
- iBOT的块级损失关注局部patch特征。
- 如果使用同一个头,优化方向会相互干扰,导致全局与局部特征难以同时优化。
独立投影头允许DINO和iBOT在大规模自监督训练中各自优化自己的特征目标,从而提升全局和局部特征的表达能力,同时提高下游任务的性能。
3.2.2 Sinkhorn-Knopp 中心化
DINO和iBOT使用教师网络输出的softmax分布做中心化,然而,这种方式的EMA center是单一向量,无法强制batch内特征分布均匀,对于大batch或高维输出向量,可能出现输出向量某些维度几乎不被激活,分布不平衡。
Sinkhorn-Knopp是一种迭代式的矩阵归一化算法,最早在SwAV中使用,用于保证特征在无监督学习中的均衡分布。它的输入和DINO中心化方法的输入一样也是一个[batch_size, out_dim]的tensor。
Sinkhorn-Knopp会迭代调整矩阵,使输出向量的每个维度(原型,prototype)在batch内的总概率均衡,迭代多次后,得到一个双向归一化矩阵。通过强制batch内每个输出向量的维度都被充分利用,使特征分布更均匀,从而增强判别能力。
以下举例说明Sinkhorn-Knopp和DINO/iBOT中心化的区别:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
| import torch
import torch.nn.functional as F
torch.manual_seed(42)
batch_size = 4
out_dim = 10
patch_out_dim = 10
n_patches = 8
mask_indices = [1, 3, 5]
student_temp = 0.1
teacher_temp = 0.04
student_class_token = torch.randn(batch_size, out_dim)
teacher_class_token = torch.randn(batch_size, out_dim)
student_patch_tokens = torch.randn(batch_size, n_patches, patch_out_dim)
teacher_patch_tokens = torch.randn(batch_size, n_patches, patch_out_dim)
c = torch.zeros(out_dim)
def dino_centering(teacher_out, student_out, teacher_temp=0.04, student_temp=0.1, center=c):
teacher_probs = F.softmax((teacher_out - center) / teacher_temp, dim=1)
student_probs = F.softmax(student_out / student_temp, dim=1)
loss = -(teacher_probs * student_probs.log()).sum(dim=1).mean()
return teacher_probs, student_probs, loss
def ibot_centering(teacher_patch, student_patch, mask_indices, teacher_temp=0.04, student_temp=0.1, center=c):
student_mask_tokens = student_patch[:, mask_indices, :]
teacher_visible_tokens = teacher_patch[:, mask_indices, :]
teacher_probs = F.softmax((teacher_visible_tokens - center) / teacher_temp, dim=2)
student_probs = F.softmax(student_mask_tokens / student_temp, dim=2)
loss = -(teacher_probs * student_probs.log()).sum(dim=2).mean()
return teacher_probs, student_probs, loss
def sinkhorn_knopp_centering(teacher_out, student_out, student_temp=0.1, n_iters=3, epsilon=1e-6):
Q = torch.exp(teacher_out / 0.05).t()
Q /= Q.sum()
r = torch.ones(Q.shape[0], device=Q.device) / Q.shape[0]
c_vec = torch.ones(Q.shape[1], device=Q.device) / Q.shape[1]
for _ in range(n_iters):
Q /= (Q.sum(dim=1, keepdim=True) + epsilon)
Q *= r.view(-1, 1)
Q /= (Q.sum(dim=0, keepdim=True) + epsilon)
Q *= c_vec.view(1, -1)
teacher_probs = Q.t()
student_probs = F.softmax(student_out / student_temp, dim=1)
loss = -(teacher_probs * student_probs.log()).sum(dim=1).mean()
return teacher_probs, student_probs, loss
t_dino, s_dino, loss_dino = dino_centering(teacher_class_token, student_class_token)
t_ibot, s_ibot, loss_ibot = ibot_centering(teacher_patch_tokens, student_patch_tokens, mask_indices)
t_sk, s_sk, loss_sk = sinkhorn_knopp_centering(teacher_class_token, student_class_token)
print("DINO Loss:", loss_dino.item())
print("iBOT Loss:", loss_ibot.item())
print("SK Loss:", loss_sk.item())
print("Teacher probs DINO shape:", t_dino.shape)
print("Student probs DINO shape:", s_dino.shape)
print("Teacher probs iBOT shape:", t_ibot.shape)
print("Student probs iBOT shape:", s_ibot.shape)
print("Teacher probs SK shape:", t_sk.shape)
print("Student probs SK shape:", s_sk.shape)
|
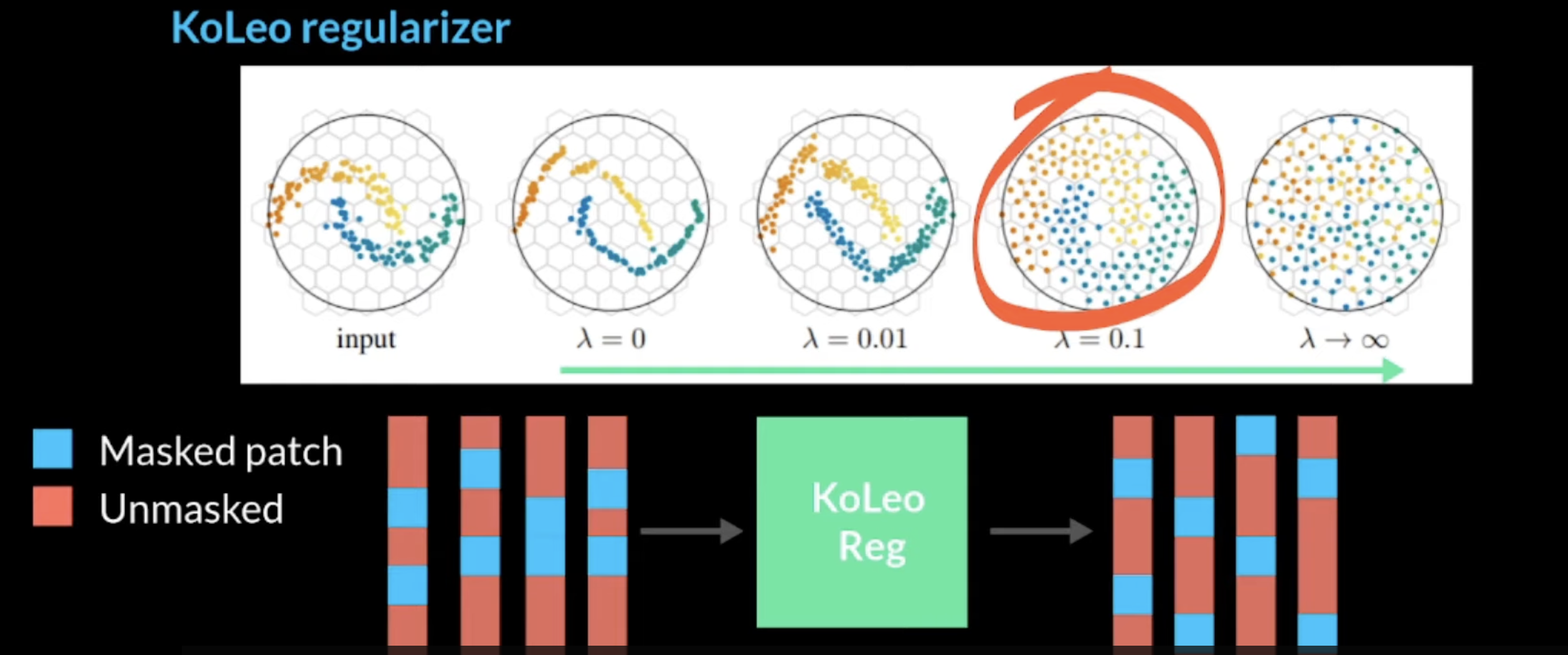
3.2.3 KoLeo 正则化
KoLeo 正则化项是加在总的loss中的,它直接操作embedding,无需后续的softmax,它可以使得batch内特征在向量空间中均匀分布,避免特征坍塌。
具体的原理为:对batch内每个向量,经过L2归一化之后,计算它与最近邻的距离,最大化最小距离。
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| def koleo_loss(features):
"""
features: [batch, num_patches, dim] 或 [batch, dim]
自动展开 batch * num_patches
"""
if features.dim() == 3:
batch, num_patches, dim = features.shape
features = features.reshape(batch * num_patches, dim)
features = F.normalize(features, p=2, dim=1)
N = features.size(0)
dist = torch.cdist(features, features, p=2)
mask = torch.eye(N, device=features.device).bool()
dist.masked_fill_(mask, float('inf'))
d_min, _ = dist.min(dim=1)
loss = -torch.log(d_min).mean()
return loss
|
举个例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
| import torch
import torch.nn as nn
import torch.nn.functional as F
def koleo_loss(features):
"""
features: [batch, num_patches, dim] 或 [batch, dim]
自动展开 batch * num_patches
"""
if features.dim() == 3:
batch, num_patches, dim = features.shape
features = features.reshape(batch * num_patches, dim)
features = F.normalize(features, p=2, dim=1)
N = features.size(0)
dist = torch.cdist(features, features, p=2)
mask = torch.eye(N, device=features.device).bool()
dist.masked_fill_(mask, float('inf'))
d_min, _ = dist.min(dim=1)
loss = -torch.log(d_min).mean()
return loss
def dino_loss(student_class, teacher_class, center, temp=0.1):
"""
student_class: [batch, out_dim]
teacher_class: [batch, out_dim]
center: [1, out_dim]
"""
teacher_probs = F.softmax((teacher_class - center) / temp, dim=1)
student_probs = F.log_softmax(student_class / temp, dim=1)
loss = -(teacher_probs * student_probs).sum(dim=1).mean()
return loss
def ibot_patch_loss(student_patch, teacher_patch, center, temp=0.1):
"""
student_patch: [batch, num_patches, patch_out_dim]
teacher_patch: [batch, num_patches, patch_out_dim]
center: [1, patch_out_dim]
"""
batch, num_patches, dim = student_patch.shape
student_patch_flat = student_patch.reshape(batch*num_patches, dim)
teacher_patch_flat = teacher_patch.reshape(batch*num_patches, dim)
teacher_probs = F.softmax((teacher_patch_flat - center) / temp, dim=1)
student_probs = F.log_softmax(student_patch_flat / temp, dim=1)
loss = -(teacher_probs * student_probs).sum(dim=1).mean()
return loss
batch_size = 8
out_dim = 128
num_patches = 16
patch_out_dim = 64
student_class = torch.randn(batch_size, out_dim)
teacher_class = torch.randn(batch_size, out_dim)
student_patch = torch.randn(batch_size, num_patches, patch_out_dim)
teacher_patch = torch.randn(batch_size, num_patches, patch_out_dim)
center_class = torch.zeros(1, out_dim)
center_patch = torch.zeros(1, patch_out_dim)
lambda_ibot = 1.0
lambda_koleo = 0.1
temp = 0.1
loss_class = dino_loss(student_class, teacher_class, center_class, temp)
loss_patch = ibot_patch_loss(student_patch, teacher_patch, center_patch, temp)
loss_koleo_class = koleo_loss(student_class)
loss_koleo_patch = koleo_loss(student_patch)
loss_total = loss_class + lambda_ibot * loss_patch + lambda_koleo * (loss_koleo_class + loss_koleo_patch)
print("Loss DINO/class-level:", loss_class.item())
print("Loss iBOT/patch-level:", loss_patch.item())
print("Loss KoLeo/class:", loss_koleo_class.item())
print("Loss KoLeo/patch:", loss_koleo_patch.item())
print("Loss total:", loss_total.item())
optimizer = torch.optim.Adam([student_class, student_patch], lr=1e-3)
optimizer.zero_grad()
loss_total.backward()
optimizer.step()
|
3.2.4 高分辨率短时训练策略
提高图像分辨率对于像素级下游任务(如分割或检测)至关重要,在这些任务中,小物体在低分辨率下会消失。然而,在高分辨率下训练既耗时又耗内存,因此,DINOv2在预训练结束时的短时间内将图像分辨率增加到518×518,最终得到的模型既高效又能适应下游像素级任务.
四、DINOv2的工程优化trick
引入了FlashAttention,替换标准的self-attention层。
使用Sequence Packings来同时执行全局视图和局部视图的前向推理过程。
举个直观的比喻:
可以把每个序列看成一条“火车”,长度不同:大裁剪=196个token,小裁剪=49个token
原方法:分别让两列火车独立通过 Transformer,比较低效
Sequence Packing:把火车连接成一列长火车,用隔板(block-diagonal mask)分隔,从而可以并行计算但不会互相干扰
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| import torch
import torch.nn.functional as F
def sequence_packing_forward(student_tokens_list, transformer):
"""
将不同长度的 token 序列打包一起前向 Transformer
Args:
student_tokens_list: list of tensor, 每个 tensor shape [B, L_i, C]
- B: batch size
- L_i: 当前裁剪 token 数量
- C: token embedding 维度
transformer: transformer 模块
Returns:
output: 打包后的 transformer 输出, shape [B, L_total, C]
"""
B = student_tokens_list[0].shape[0]
C = student_tokens_list[0].shape[2]
L_list = [tokens.shape[1] for tokens in student_tokens_list]
L_total = sum(L_list)
packed_tokens = torch.cat(student_tokens_list, dim=1)
mask = torch.ones(B, L_total, L_total, device=packed_tokens.device, dtype=torch.bool)
start = 0
for L in L_list:
mask[:, start:start+L, start:start+L] = False
start += L
output = transformer(packed_tokens, attention_mask=mask)
outputs_list = []
start = 0
for L in L_list:
outputs_list.append(output[:, start:start+L, :])
start += L
return outputs_list
|
- 使用PyTorch2.0中的Fully-Shareded Data Parallel(FSDP)将模型切分到不同的GPU上。
- 通过知识蒸馏将大模型,比如ViT-G,蒸馏到小模型,比如ViT-L。
参考:





