从零开始实现YOLOv3
YOLOv1 vs YOLOv3
| 特性 | YOLOv1 | YOLOv3 |
|---|---|---|
| 基础网络 | GoogLeNet(Inception v1) | Darknet-53(基于ResNet) |
| 多尺度预测 | 无(只将原图划分为7x7的网格) | 支持多尺度预测(13x13, 26x26, 52x52,这些数字是不同特征图的尺寸) |
| 锚框 | 无 | 使用锚框进行预测 |
| 损失函数 | 简单的均方误差MSE | 改进的损失函数(MSE –> 交叉熵),增加了类别和置信度的加权 |
| 检测精度 | 较低,尤其对小物体检测较差 | 提高了精度,尤其对小物体检测能力增强。 13 x 13 层负责检测大型物体,52 x 52 层检测较小的物体,26 x 26 层检测中型物体。 |
| 速度 | 非常快,适合实时检测 | 较快,但相比YOLOv1稍慢 |
| 分类能力 | 适合少量类别(例如20个类别) | 支持多类别(例如COCO的80类) |
| 定位精度 | 定位精度较差,特别是小物体 | 定位精度提高,能更好地处理各种物体尺寸。 |
| 模型大小 | 相对较小,适合资源有限的设备 | 相对较大,精度和速度有所提升 |
YOLOv1直接回归预测box,YOLOv3回归的是相对于anchor的偏移量,在anchor上施加上预测偏移量,才是模型真正的预测box。
一、网络结构
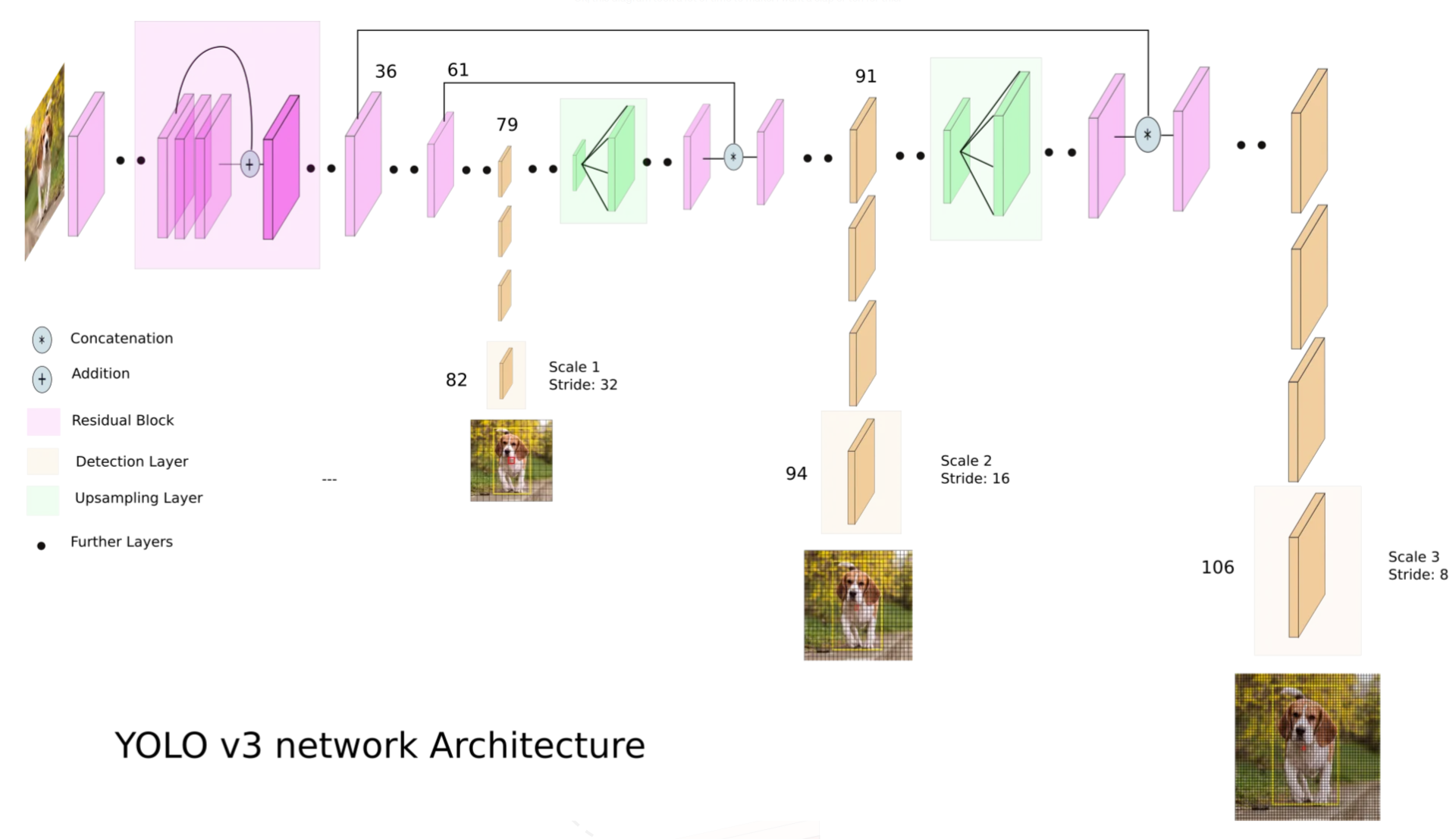
YOLOv3的网络结构如上图所示,提取出相应的网络结构配置文件config。
其中:
- 元组对应的是卷积层的(out_channels,kernel_size,stride)
- 列表的第一个元素B代表ResidualBlock,第二个元素代表该ResidualBlock重复的次数
- “S”代表ScalePrediction层,总共有3个,对应3种不同尺度特征图,每个ScalePrediction层的输出是SxS(在论文中,S分别为13,26,52)的特征图,可视为SxS的网格,每个网格负责预测B=3个不同的anchor,每个anchor对应num_classes + 5(类别分布+置信度+xywh)
- “U”代表上采样层,如图中绿色框所示,用于将特征图上采样后与前面层的特征图进行拼接融合
1 | config = [ |
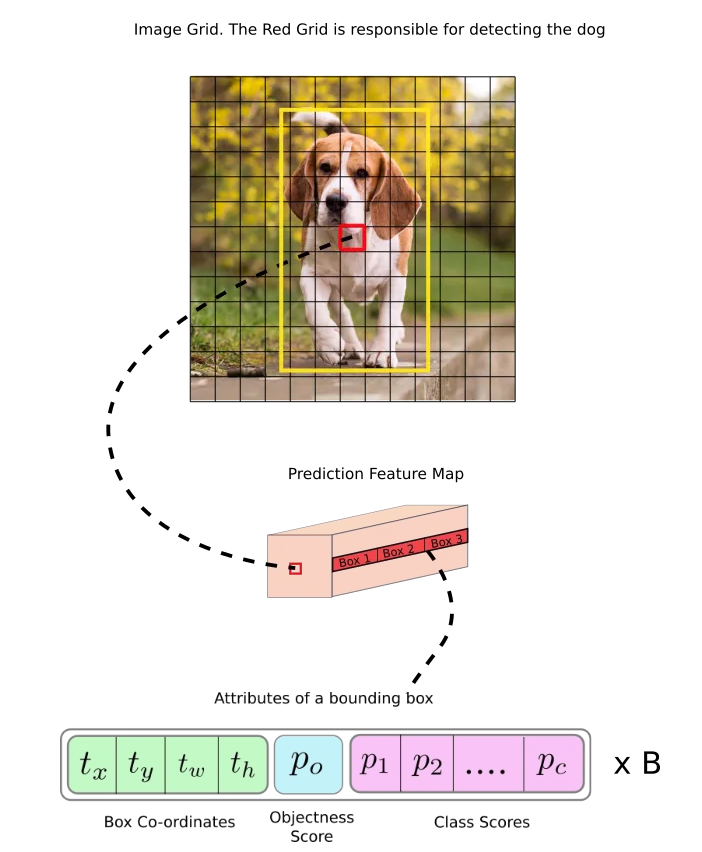
下面这张图展示了在13x13尺度特征图上,负责预测dog的grid cell的预测输出格式,包括B个bbox的信息,其中每个信息的维度是4+1+C(xywh+confidene+classes).
现在来代码实现YOLOv3的网络结构:
1 |
|
二、数据加载器
打开一个标注文件:

YOLOv3总共有3个输出层用于loss计算,这些输出层被称为Scale Predicton(这里简记为scale,便于书写),每个scale都是输入图片下采样得到的,尺寸分别为13X13,26X26,52X52。
每个scale都可以视为将原图划分为了SxS(S=13,26,52)大小的网格,每个网格预设3个anchor,每个anchor包含6个元素:置信度(0 or1),xywh,目标类别。
为了计算loss,在加载数据时,和YOLOv1一样,需要使用标注文件中的box信息,制作一个和模型预测结果shape基本一致的”框架”,如下:
1 | targets = [torch.zeros((self.num_anchors // 3, S, S, 6)) for S in self.S] |
以上代码仅做了初始化,接下来需要使用标注文件中的box信息对targets进行填充。
具体来说,针对一个标注txt文件中的每一条box信息:
- 首先计算当前标注box与3个scale上3个anchor的IoU,总共9个anchor,相应可得到9个IoU值,并从大到小排序(优先匹配IoU高的anchor)。这里,由于标注box和anchor都是归一化的,因此可以直接计算IoU。
- 然后,遍历所有的9个anchor,分别确定每个anchor所属的scale,以及当前标注box在这个scale中的行列位置信息i,j,并将相对于原图的标注box信息转换到相对网格的(此时称该网格负责预测当前box,其实就是算一下当前box在scale中的行和列,这个scale是可以看作被划分为SxS的网格的,因此行和列其实就是网格上的位置坐标,比如scale对应的特征图是下采样了20倍的,那么一个网格就对应原图中的20个像素。虽然一个scale上有SxS个网格,但是只有这个网格与标注box比较接近,即两者IoU最大,因此,这个scale上除了该匹配网格之外,其它网格是没有与之匹配的标注box的,因此就不用填充了)。
注意,针对每个标注box,在每个scale上都会有一个anchor与之匹配,因此使用了 has_anchor = [False] * 3来确保每个scale上的anchor都已与之匹配。
在上述对某个标注box进行匹配时,可以将所有的anchor划分为3类:
- 正样本
- 负样本
- 忽略样本
具体来说,对于每一个标注bbox,在3个scale中,每个scale下都有1个anchor与之匹配,这就是正样本。此外,每个scale中还有剩余的2个anchor,如果这两个anchor与标注bbox的IoU都比较小,那么就是负样本。但是,如果剩余的某个anchor与标注box的IoU也比较大,此时按理来说它应该是正样本,但是当前标注box已经与另一个anchor匹配了,并且与另一个anchor的IoU更大,因此即使当前anchor与标注box的IOU也有点大,但已经没有可以与之匹配的标注box了,因此需要忽略当前的anchor(confidence设置为-1做个标记),不参与loss计算。
1 | """ |
三、损失函数
每一个scale都会单独计算一个loss。
loss计算公式和v1的组成类似(都是置信度(OBJ,noOBJ)+坐标+分类3部分损失),v3的分类损失用的交叉熵而不是MSE)。但是,在计算边界框坐标损失的时候,v1是直接预测box的xywh,而v3预测的是xywh的偏移量,然后将这些偏移量施加到预设的anchor上进行变换,得到最终的预测box。
变换公式如下:

target中的xy已经是相对于anchor的了(详见YOLODataset类,且3个anchor的中心点xy是一样的),因此在loss计算代码中,只需要将预测的xy偏移量进行sigmoid变换,而不需要再加上anchor的中心点坐标。
1 | class YoloLoss(nn.Module): |
四、训练
和v1类似,训练代码也是很常规的,直接贴过来:
1 | def train_fn(train_loader, model, optimizer, loss_fn, scaler, scaled_anchors): |
以上就是本文关于YOLOv3的介绍。










