从零开始实现YOLOv1
一、核心思想
- YOLOv1 的核心思想是将目标检测问题视为一个回归问题,是一个直接从图像像素到边界框坐标及类别的映射。
- 输入图像通过一个单一的CNN进行处理,网络将图像划分为多个网格,每个网格负责检测图像中一个目标。
- 每个网格输出一个固定数量(B)的边界框和类别概率分布。
具体来说,Yolov1将一个448x448的原图片分割为7x7=49个网格(grid cell),每个grid cell预测:
- B(论文中B=2)个边界框(bbox)的坐标(x,y,w,h)
- B个bbox内各自是否包含目标的置信度confidence
- 1个类别概率分布C
YOLOv1使用的训练集为pascal VOC2012,总共20个类别,因此每一个grid cell对应 (4+1)x2+20=30个预测参数。
二、标签格式
标签分为预测标签prediction和真实标签target.
target
首先明确,每个物体都有一个中心点,如下图蓝色点所示。
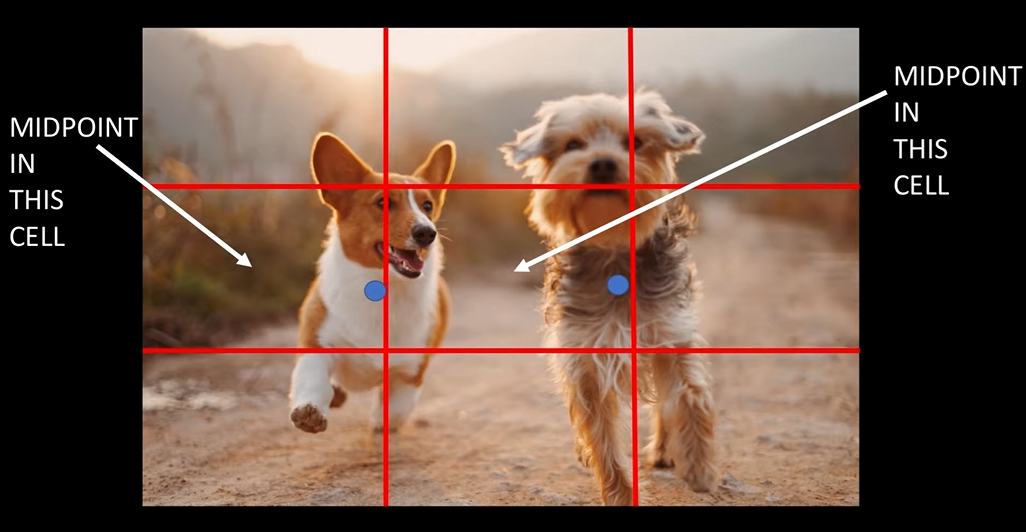
每个gird cell都只负责预测某物体中心点落入该grid cell的物体。
比如左侧狗子的中心点落入了第二行第一列的grid cell,将其单独取出来:

这里的 [x,y,w,h]是相对于该grid cell的左上角点(0,0)的,在上面的例子中,可能的值是[0.95,0.55,0.5,1.5],如下图绿色框所示
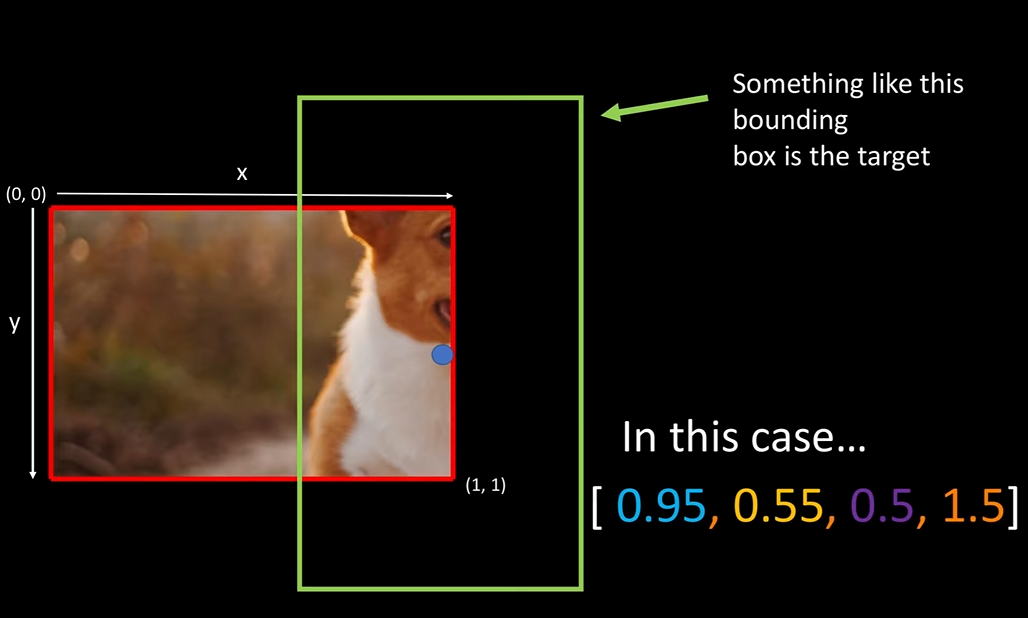
因此,每个grid cell对应的target标签为:

prediction
预测标签prediction和target很像,只不过,prediction会预测2个bbox(以应对目标可能的两种比例:长>宽 or宽>长).
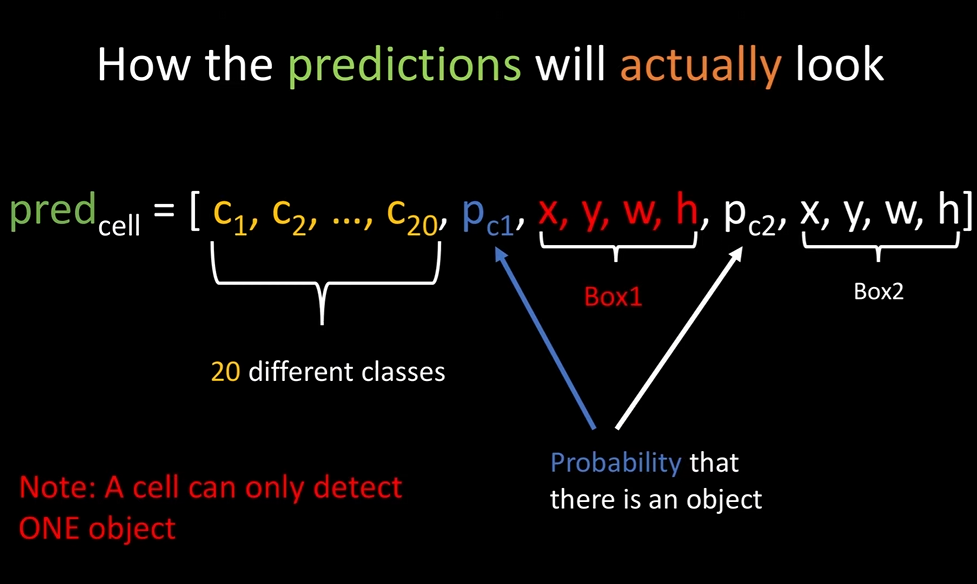
对比target和prediction
以上所介绍的均对于一个grid cell,而YOLOv1中将图像划分成了SxS个grid cell,因此,对于一张图片来说:
- target的shape:[S,S,4+1+20=25]
- prediction的shape:[S,S,2*(4+1)+20=30]
三、网络结构
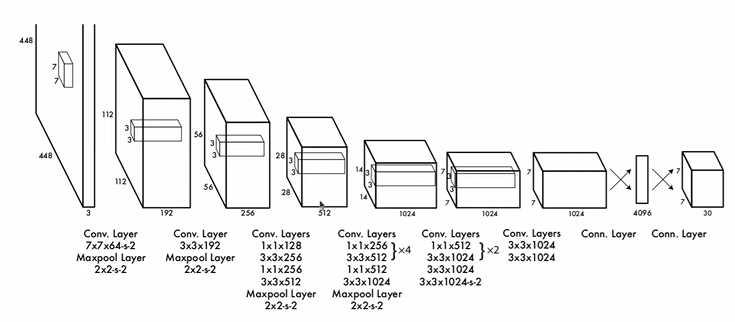
YOLOv1的网络结构很简单,直接上代码:
1 |
|
四、数据加载器
打开一个标签文件:

每一张图片对应一个.txt标注文件,标注文件中的每一行代表一个目标的信息(比如当前文件表明000001.png中包含两个目标),从左到右分别是cls,x,y,w,h,并且是归一化的,这样即使图片做了resize,也不需要修改这些标注信息。
对于一张图片,模型预测结果的shape是[S,S,C+5xB]的,论文中B=2,且在划分正负样本后只有其中一个预测bbox与其对应的(如果有)的GT bbox计算loss,所以需要将上述标签文件中的信息转换成类似模型预测结果shape的格式。为此,首先搭建一个空的框架,其shape和模型预测结果shape保持一致:
1 | label_matrix = torch.zeros((self.S, self.S, self.C + 5 * self.B)) |
(真实标签target只包含1个bbox,预测标签prediction包含B=2个bbox,这里的label_matrix虽然也包含B=2个bbox,但其中一个只是起到了占位的作用,只是为了方便编写代码)
接下来,基于每张图片中的若干个bbox的标注信息,针对每一条信息,定位该目标的中心点(x,y)在SxS的grid cell中对应的行和列,行和列唯一确定了一个grid cell,该grid cell负责预测该目标,并将这些信息填充到label_matrix对应的位置。处理完这张图片中的每一条信息后,就完成了label_matrix的填充。
但是,这些标注的位置信息是相对于整张图片的,而在计算loss时,需要的位置信息是相对于grid cell的左上角点的,因此在具体填充时,需要做进一步的转换操作。
具体来说,首先查看当前GT bbox属于哪个grid cell(GT bbox的中心点(x,y)落入的那个grid cell),然后将其转换到相对于所属grid cell的位置。
以下代码实现了上述文字所描述的功能:
1 | # import torch |
这里再次总结一下YOLOv1的思路:
将图片划分为SxS个grid cell,每个grid cell负责预测B个bbox来对应GT bbox(如果有对应的GT bbox与之匹配,且一对一,B=1个正样本+1个负样本;若无GT 匹配,B=2个负样本)。这里的“负责”指的是将该网格对应的预测bbox与其匹配的GT bbox之间求loss,不断地使得该网格负责预测的bbox接近与之匹配的GT bbox。“负责”的概念,其实只是逻辑上的,具体表现在人为构建的label_matrix的shape:(self.S, self.S, self.C + 5 x self.B),正是因为人为从逻辑上将原图划分成了Sx*S个网格,才产生了“负责”的概念。模型预测SxS个grid cell的信息,上述构建的label_matrix也包含了SxS个grid cell的信息,shape已经对齐了,这样就可以计算loss了。
五、损失函数

YOLOv1的所有损失函数均采用的MSE,其中:
- 第一行和第二行:bbox损失,第一行是中心点的损失计算,第二行是宽和高的损失计算
- 第三行:正样本的置信度损失计算
- 第四行:负样本的置信度损失计算
- 第五行:正样本的预测类别损失计算
YOLOv1中的正负样本匹配策略:
总共SxS个grid cell,每个grid cell会预测B(B=2)个bbox,与GT bbox的IoU最大的预测bbox与GT bbox匹配,作为正样本参与loss计算(对应第一行、第二行和第三行)。
剩下的那个预测bbox作为负样本,只参与第四行的负样本置信度损失计算。
由于YOLOv1中每个grid cell只负责一个bbox,即使每个grid cell对应了B(B=2)个预测bbox,但是只有IoU最大的那个预测bbox才是正样本(有对应的GT bbox),因此在第五行中,只有那些正样本参与类别损失计算。
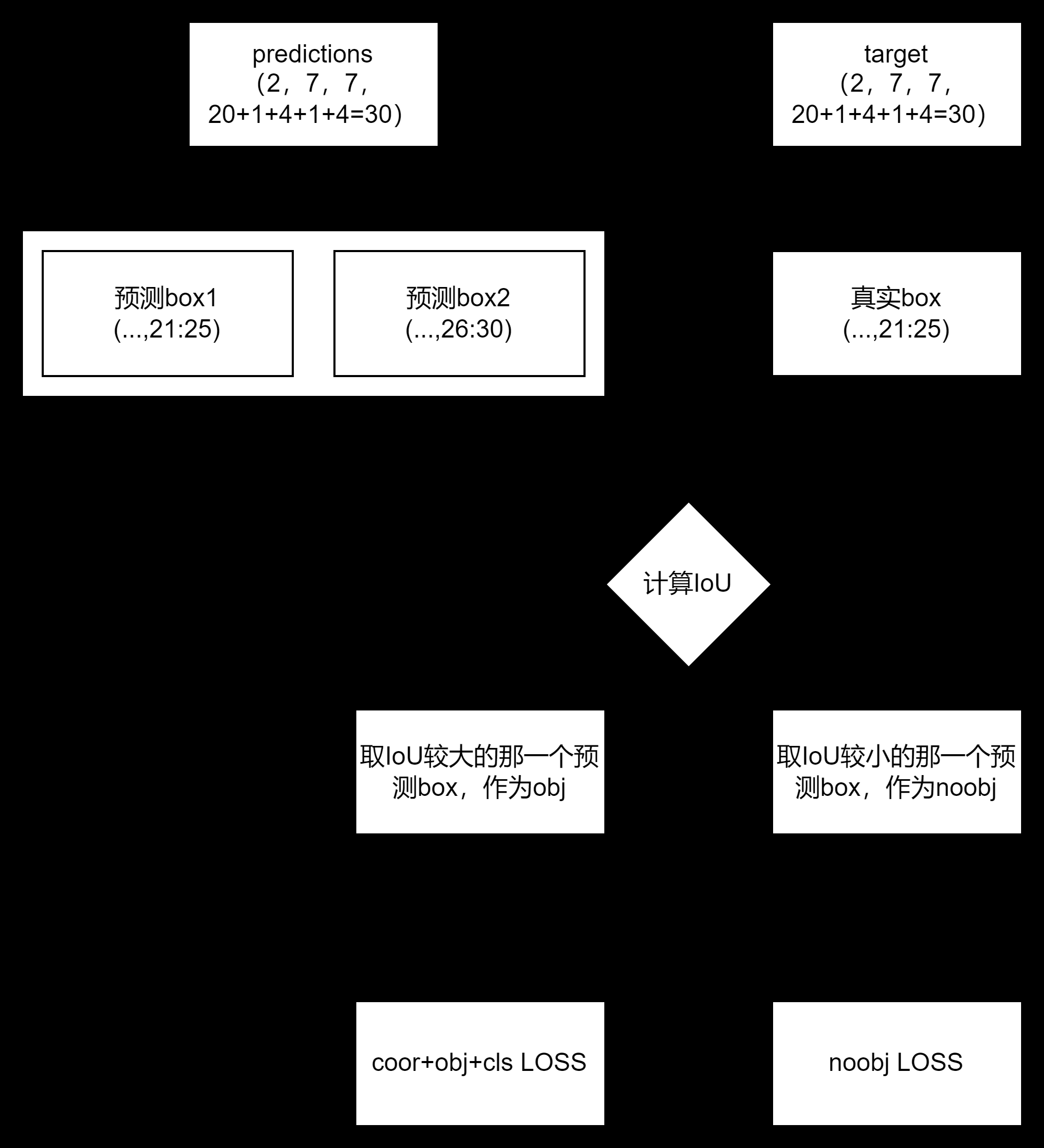
上述逻辑的代码实现如下, 一些关键细节见代码注释:
1 | import torch |
六、训练
训练代码就很常规的了,直接上代码:
1 | """ |
以上就是本文关于YOLOv1的介绍,下一篇将介绍YOLOv3.










