Tensorflow进阶
张量合并
1.拼接
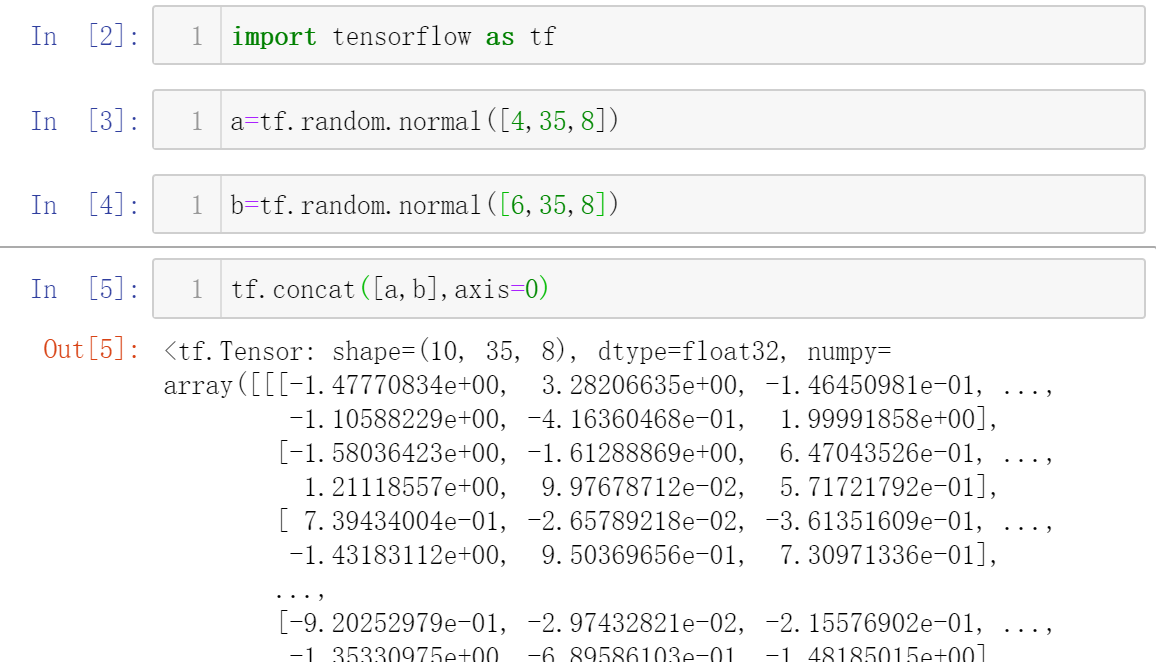
2.堆叠
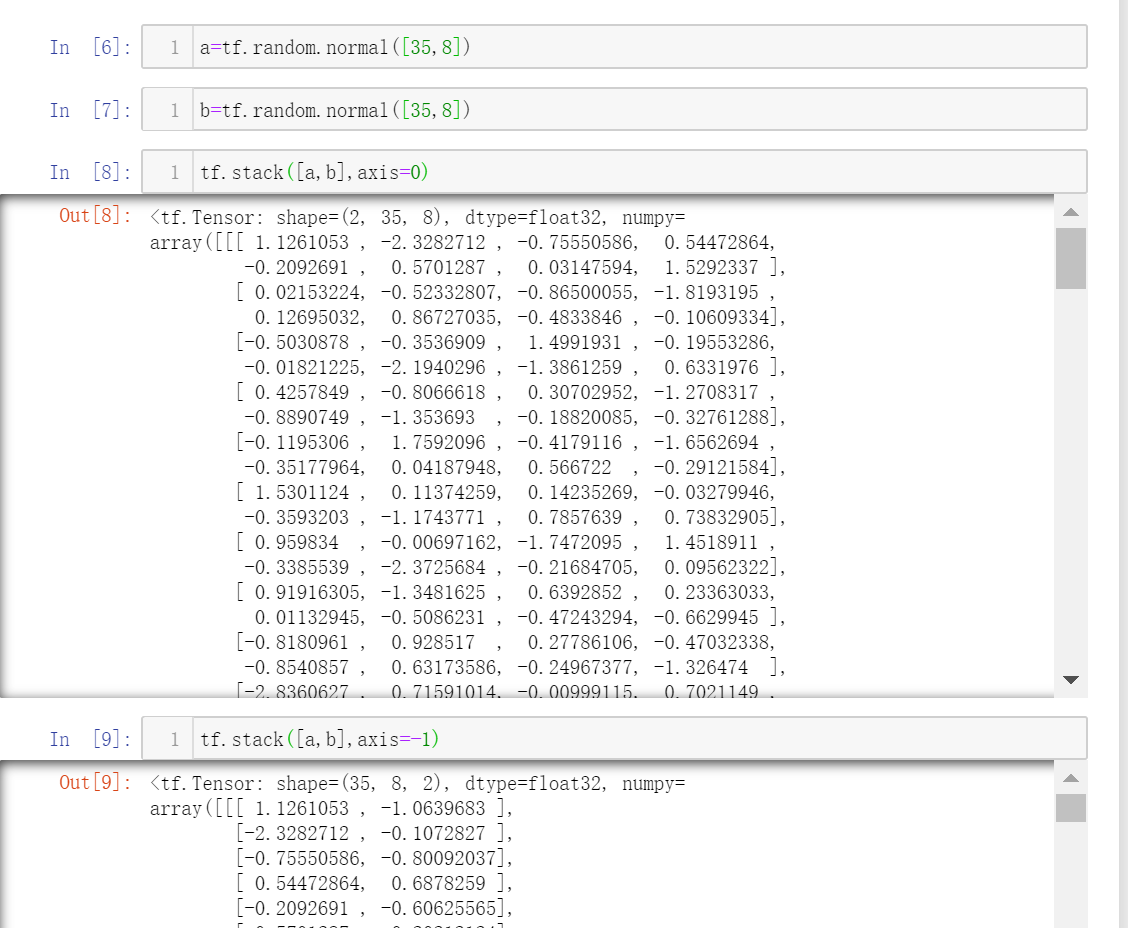
无论哪种方式,相应维度必须一致
分割
合并的逆过程
将1个张量拆成多个张量
1. split
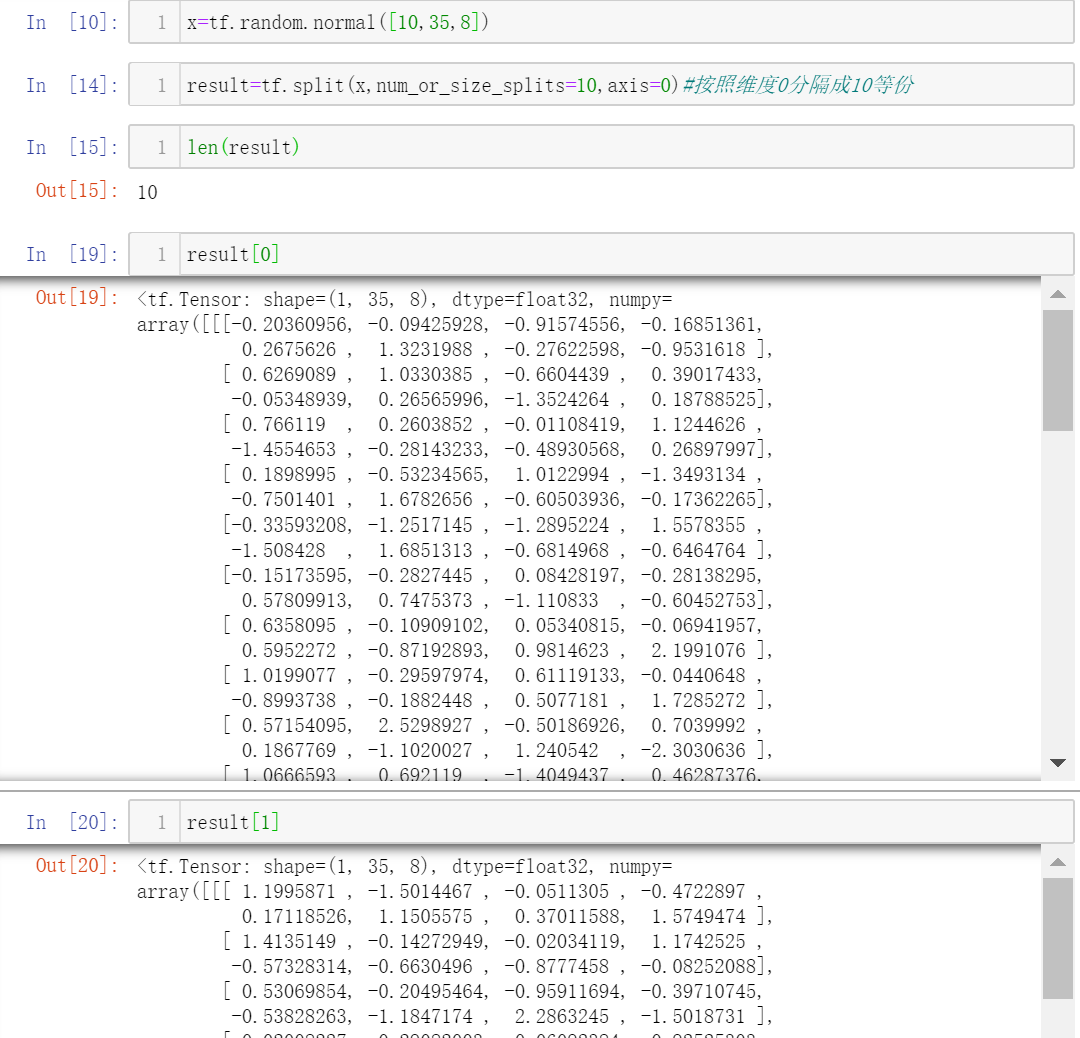
等份分割
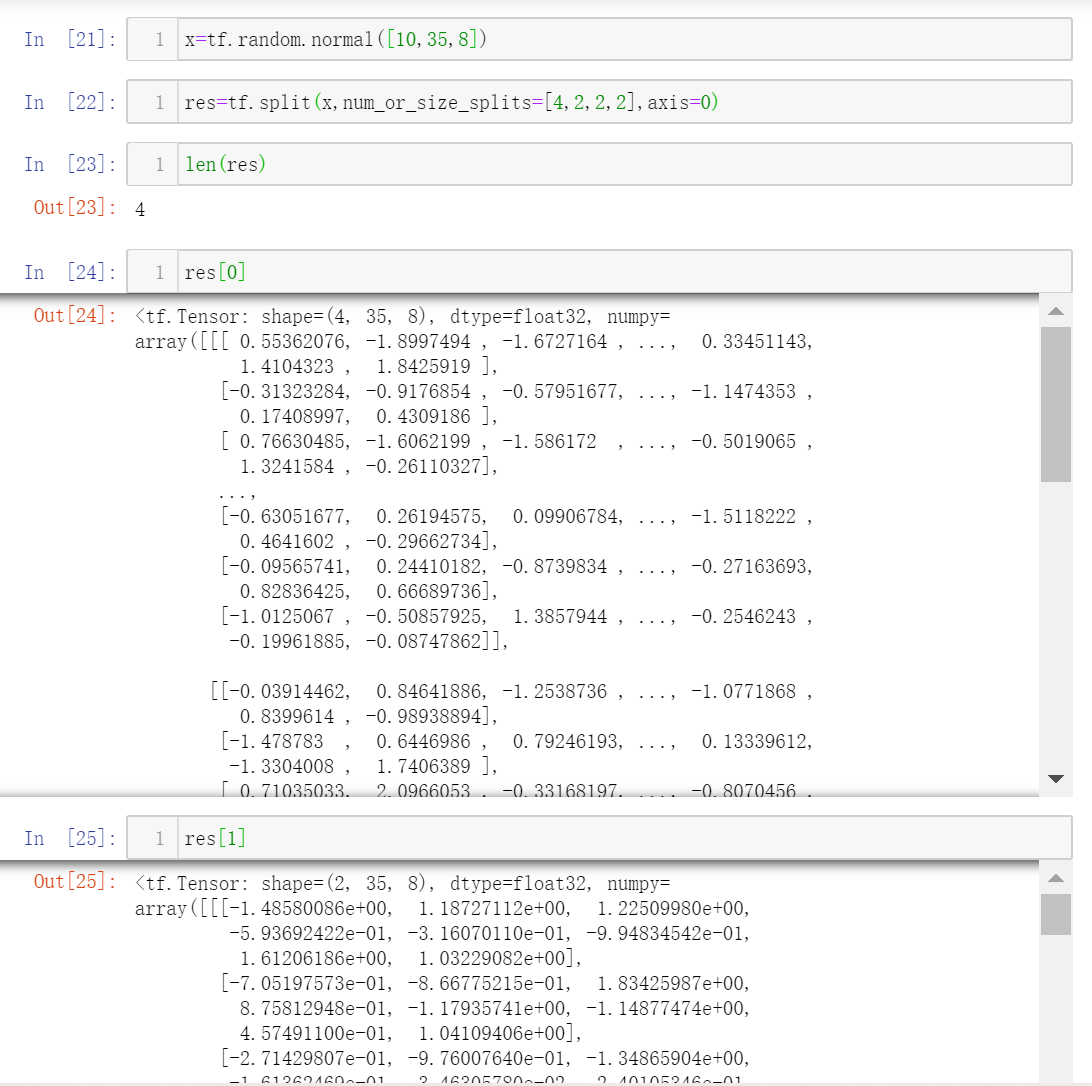
不等份分割
传入列表,表示分割后每一部分的长度
2. unstack
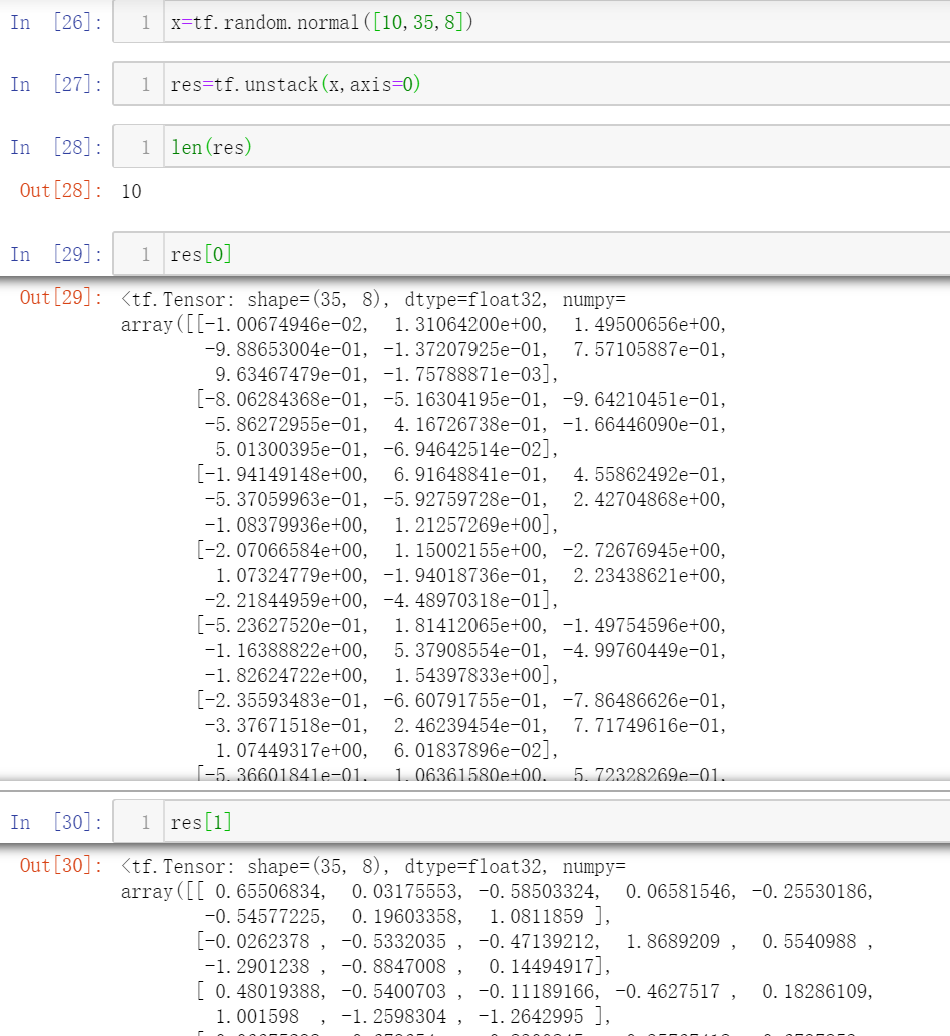
可以看出,stack是在合并张量时增加了维度,而unstack是在分割张量时减少了维度
【注意】unstack一定会将原张量按照axis指定的维度方向分割成全部的部分的长度都是1的张量,因为只有这样才能将shape中为1的维度方向去掉
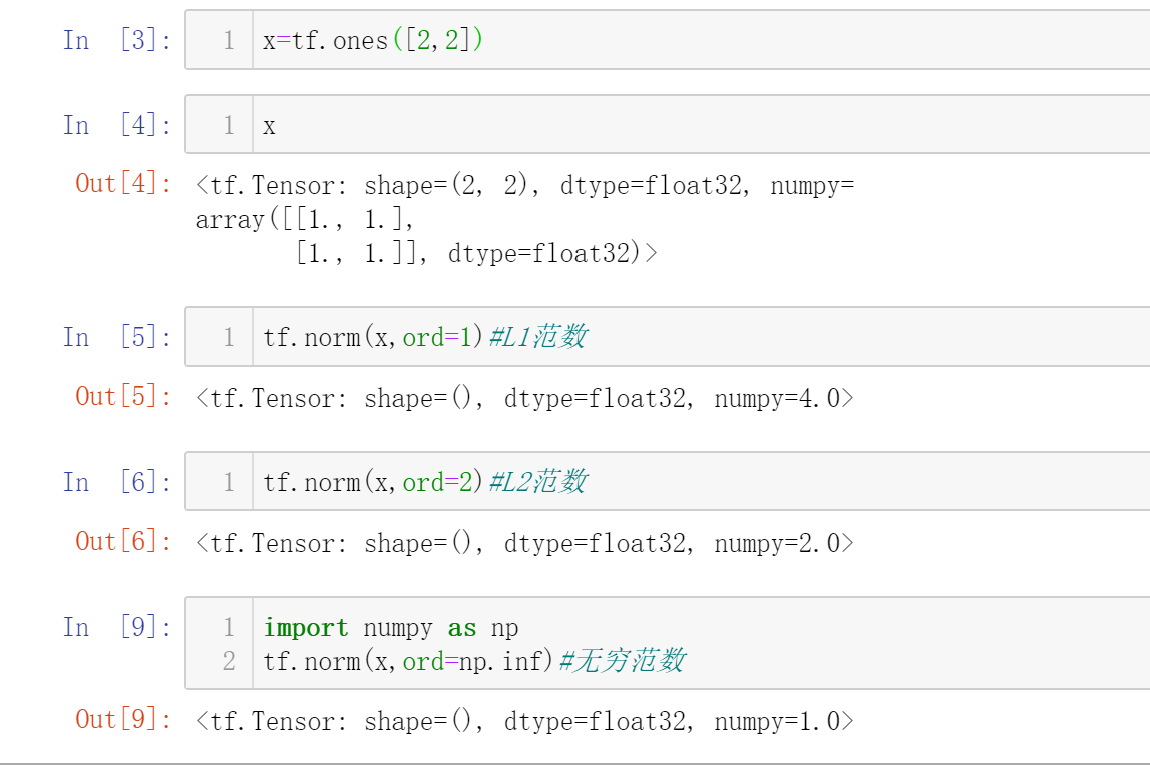
范数
主要使用L1范数、L2范数和无穷范数
常用统计量
最值:tf.reduce_max、tf.reduce_min
均值:tf.reduce_mean
和:tf.reduce_sum
指定axis

不指定axis
此时会对全局求解:

应用场景
求解所有样本的平均误差:
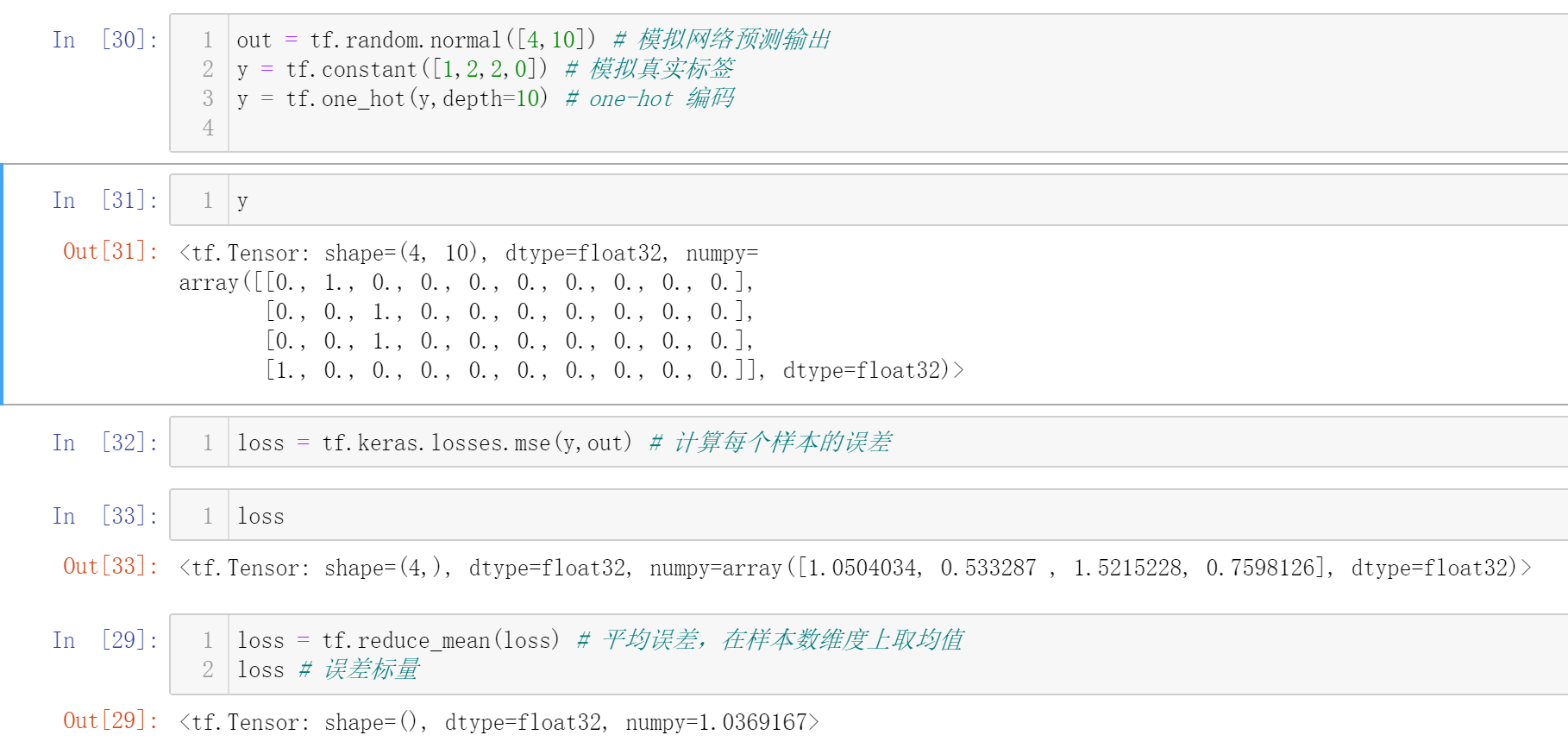
在分类问题中,求解概率最大值所在下标,即label
假设有两个样本,做10分类问题
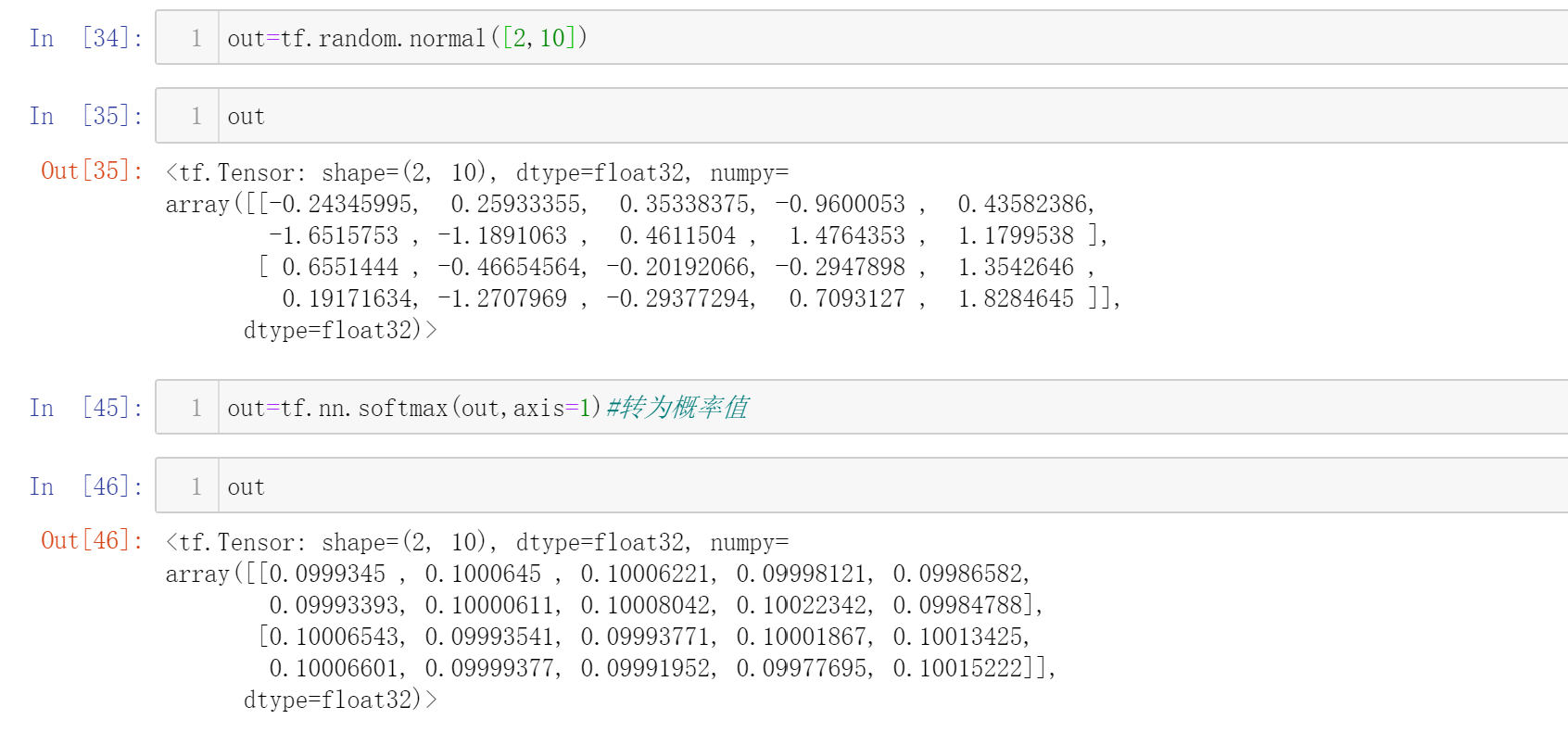
使用tf.reduce_max只能求解最大值,而使用tf.argmax可以求解最大值所在索引号(下标)

所以,这两个样本所属类别分别为8和9
张量比较
还是拿10分类的栗子,假设有100个样本
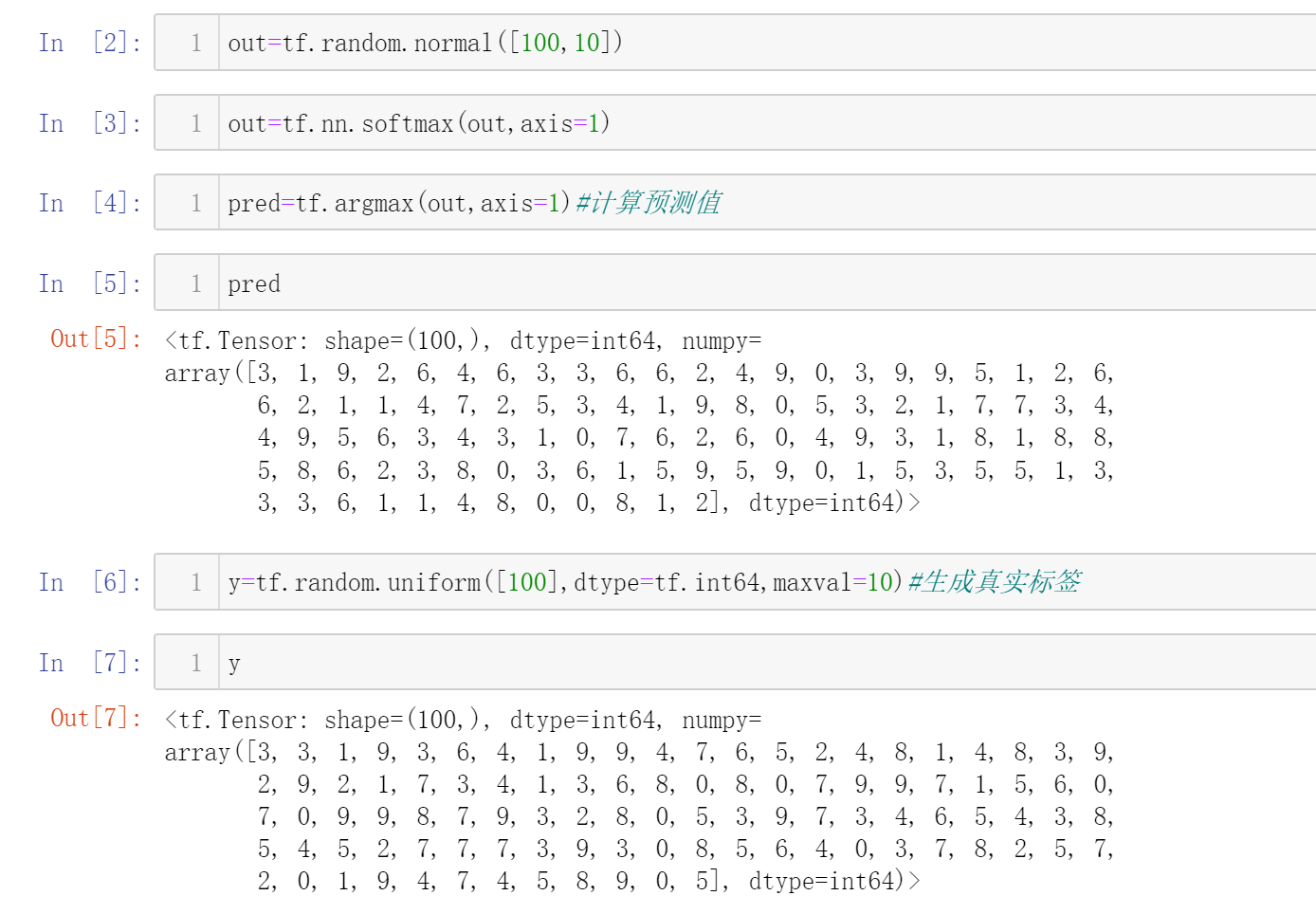
开始比较
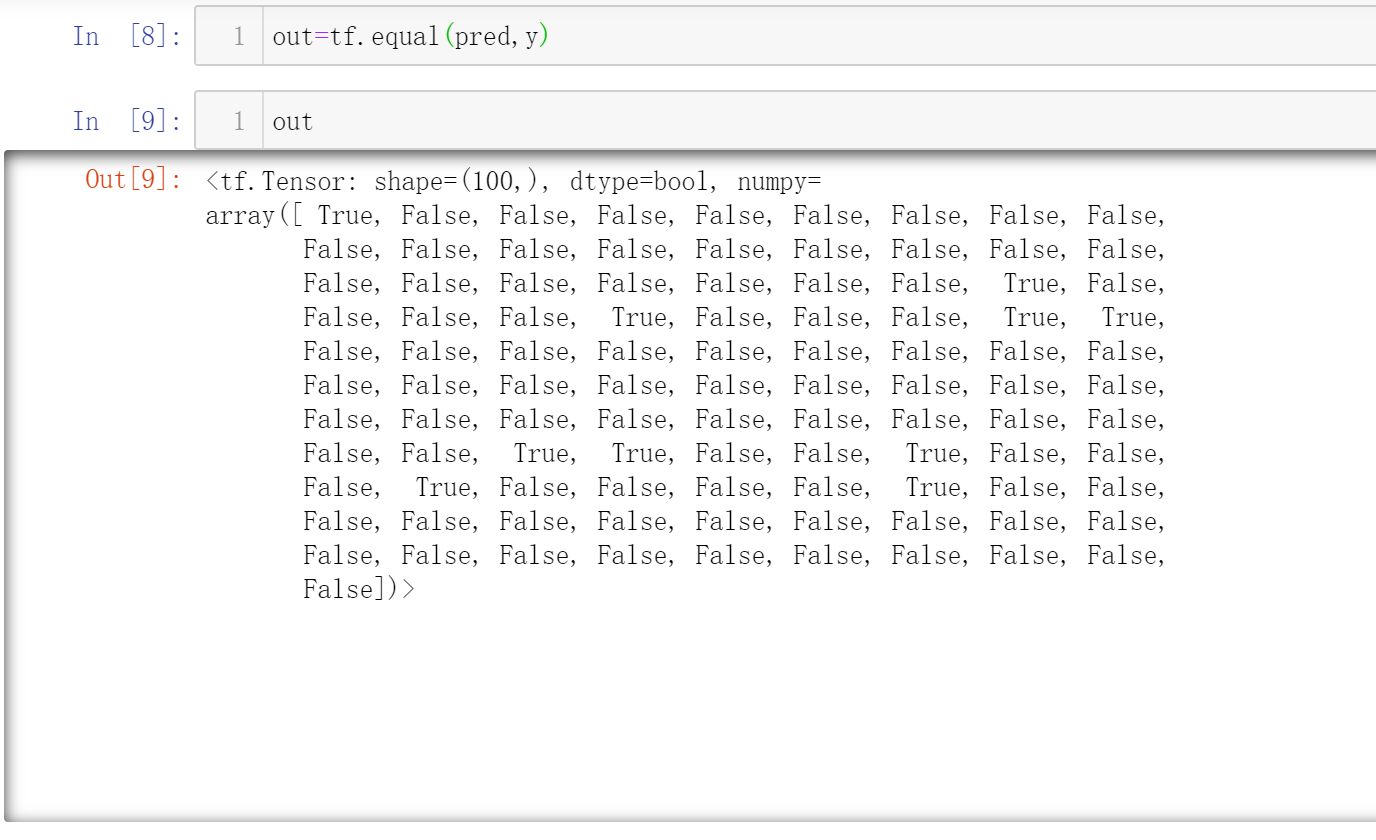
计算准确率
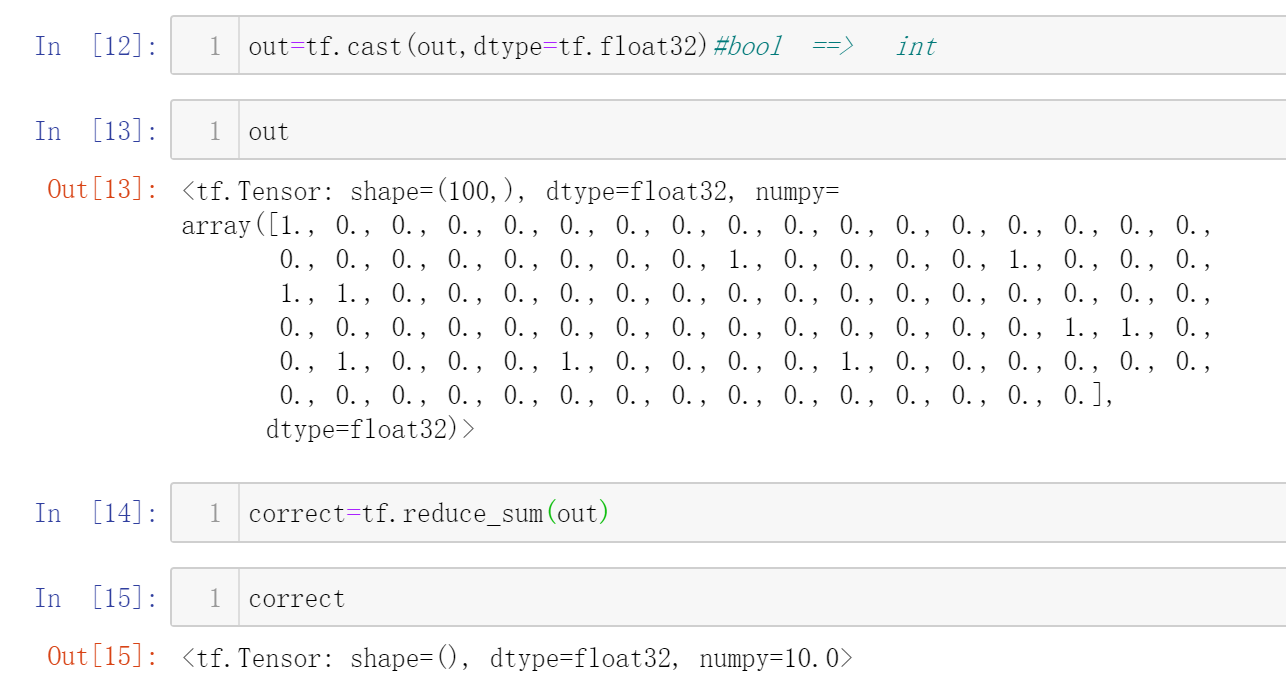
对了10个,因此准确率为10%
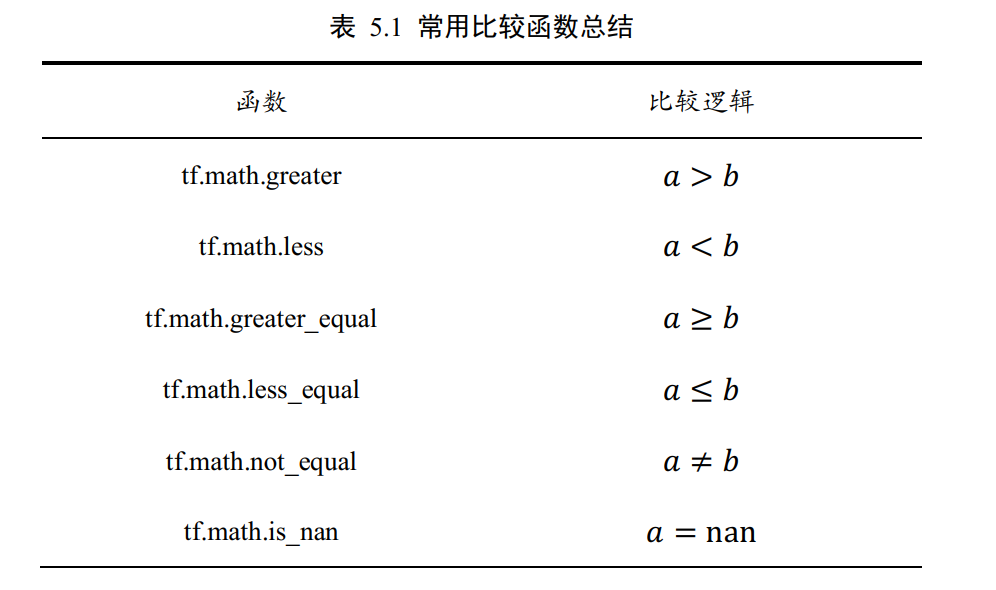
除了比较相等的 tf.equal(a, b),还有其它的比较函数,如下
填充(Padding)
使用tf.pad(x,paddings)

之后两者维度一致了,可以做Satck

常用于自然语言处理
在处理图像时,需要在多个维度进行填充,就像这样
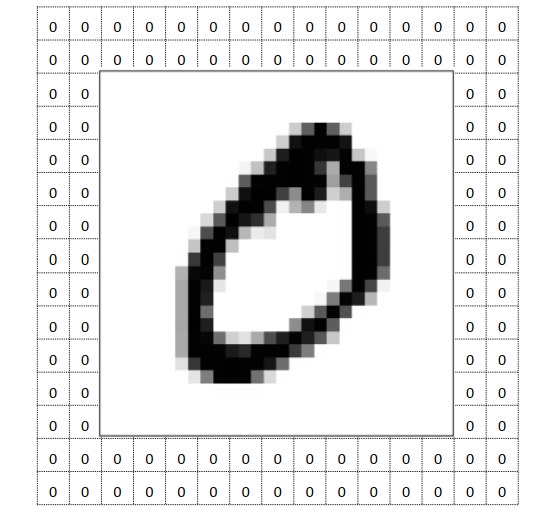
上面的图中,对width和height进行了填充,代码如下
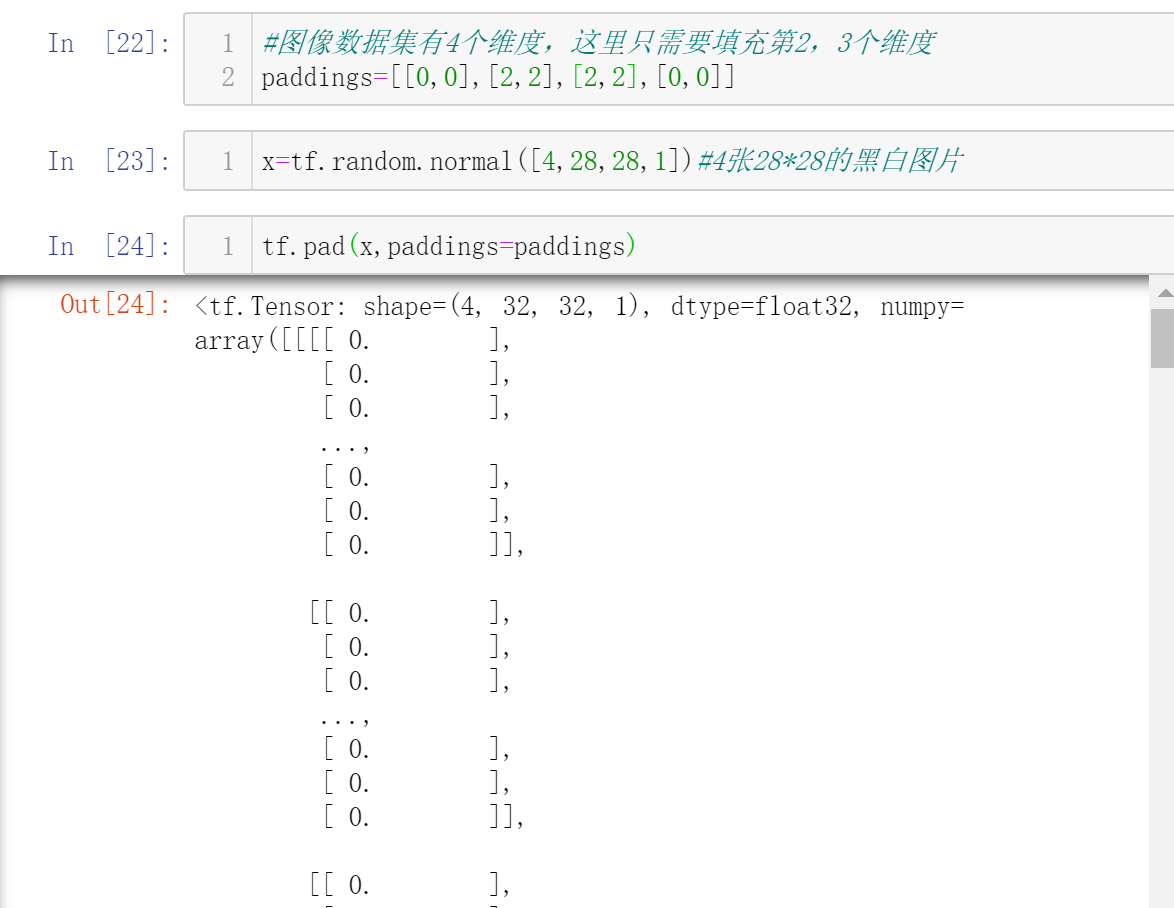
这里对width和height的开头和结尾都填充了两个0
图像由28*28变成了32*32
复制
仍旧用tf.tile()函数
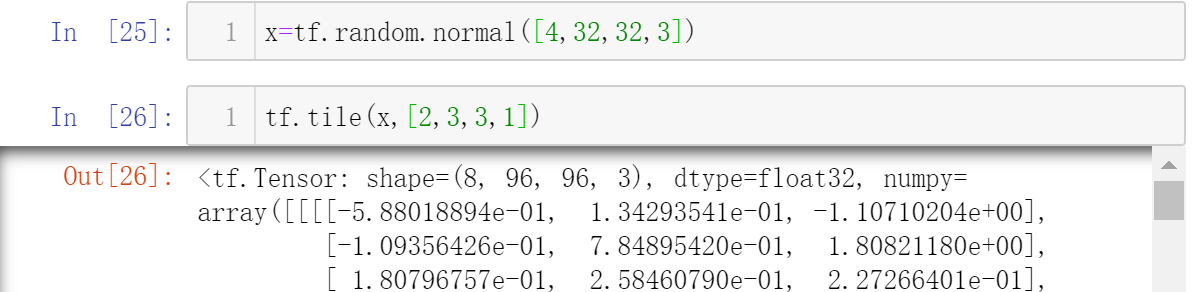
[2,3,3,1]的4个元素分别代表了4个维度要复制多少份:
1代表不复制,2代表复制1份,3代表复制2份,以此类推
数据限幅
下限幅: tf.maximum(x, a)
上限幅:tf.minimum(x, a)

应用
实现ReLU函数

实现上下限幅

另外,也可以直接使用tf.clip_by_value实现上下限幅

相关推荐

2021-04-05
1小时快速入门PyTorch
12#二话不说,先把包导入进来~import torch tensor初始化123#定义一个tensormy_tensor=torch.tensor([[1,2,3],[4,5,6]])print(my_tensor) tensor([[1, 2, 3], [4, 5, 6]]) 123#指定tensor的数据类型my_tensor=torch.tensor([[1,2,3],[4,5,6]],dtype=torch.float32)print(my_tensor) tensor([[1., 2., 3.], [4., 5., 6.]]) 123#指定devicemy_tensor=torch.tensor([[1,2,3],[4,5,6]],dtype=torch.float32,device='cuda')print(my_tensor) tensor([[1., 2., 3.], [4., 5., 6.]],...

2021-07-28
FFB6D
FFB6D: A Full Flow Bidirectional Fusion Network for 6D Pose Estimation 来源: CVPR2021代码:https://github.com/ethnhe/FFB6D 提出的问题 RGB图像+CNN:透视投影会导致几何信息损失 RDB-D+CNN::如何有效地充分利用这两种数据模式(RGB图+深度图)来进行更好的6维姿态估计? 已有的方法 使用级联思想,先从RGB中做粗略估计,再使用ICP或多视图的假设检验做后续优化。这种方法并不是端到端的方式,而且非常耗时。 使用两个网络,一个CNN,一个PCN( pointcloud network),分别从RGB图和点云文件中提取特征(croped RGB image and point cloud),然后把这两种特征concat在一起(称之为 dense features),用于姿态估计。这种混合特征的方法(concat)太naive。 也是用两个网络,CNN和PCN,只不过将特征混合方式由concat改为dense fusion,如下图: ...

2021-04-09
FaceFromX

2021-07-30
G2L-Net
G2L-Net: Global to Local Network for Real-time 6D Pose Estimation with Embedding Vector Features 来源:CVPR 2020代码:https://github.com/DC1991/G2L_Net引用量:8新版本:FS-Net(CVPR2021),还没看 提出的问题 一些基于深度学习的方法预测表现达到了sota,但做不到实时性,太慢 虽然存在一些方法能够做到实时性,但这些方法只是用了RGB图,无法处理存在遮挡和光照变化的情况 当加入深度信息后,可以处理诸如遮挡的复杂情况,但是计算密集。并且这些基于RGBD的方法的一个常见问题是:利用来自深度信息中的视点信息(view point infomation)并不是很有效,从而降低了它们的姿态估计精度。为了克服这一点,这些方法倾向于使用后细化机制( post-refinement mechanism)或假设生成/检验机制(hypotheses generation/verification...

2020-10-12
Keras中关于模型的trainable状态的问题
提出问题在看GAN的实现代码的时候,发现了这么一个地方: 123456789101112131415161718192021222324252627282930313233class GAN(): def __init__(self): self.img_rows = 28 self.img_cols = 28 self.channels = 1 self.img_shape = (self.img_rows, self.img_cols, self.channels) self.latent_dim = 100 optimizer = Adam(0.0002, 0.5) # Build and compile the discriminator self.discriminator = self.build_discriminator() ...

2020-08-16
LSTM
可以把 lstm的memory看做一个neural LSTM的解释图: 一个neural的工作过程 有点RNN的味道了 真正的LSTM




